


AI Large Model Data Labeling: Does It Outperform Humans?
Streamline data labeling with LLMs like GPT-4. Learn how to improve accuracy, efficiency, and scalability in machine learning projects using LLMs.

Data scientists spend over 80% of their time on data preparation, mainly cleaning and labeling data.
With the rise of large language models (LLMs) like GPT-4, we can now streamline this work.
In this article, we’ll explore how to use LLMs for data labeling, improving text annotation accuracy, efficiency, and scalability for better machine learning project outcomes.
LLM Data Labeling Process
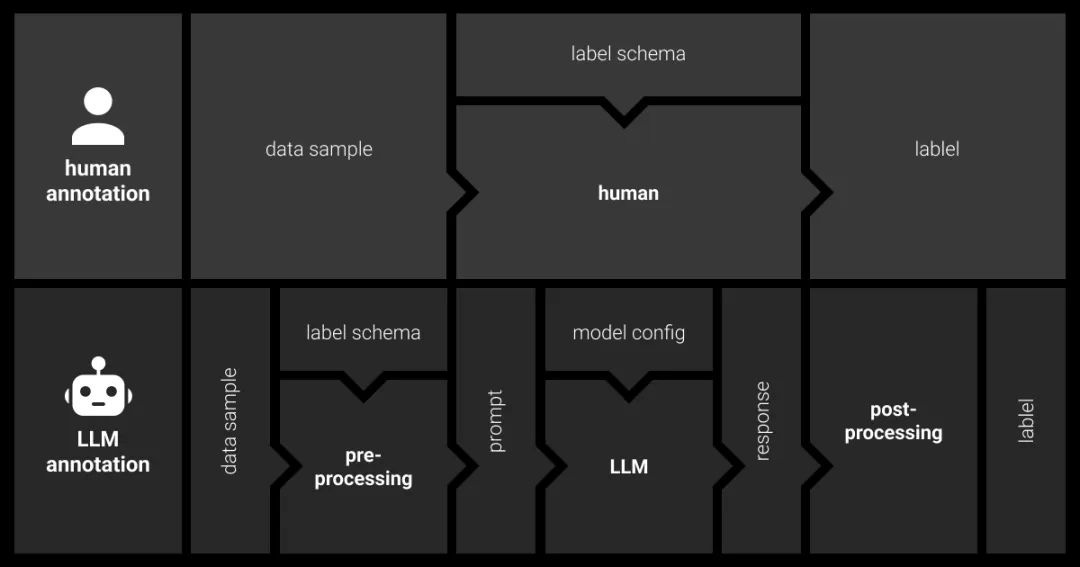
Let’s compare this to the traditional manual labeling process to better understand how LLM data labeling works.
First, you must define the labeling tasks and schema based on project goals. For instance, in named entity recognition, the schema may include labels like Person, Organization, Location, and Date.
Next, human annotators label the raw data following the guidelines.
For LLM data labeling, the process is as follows:
Model Selection: Choose an LLM (e.g., online ChatGPT or offline Llama) and configure it (e.g., set temperature parameters).
Preprocessing: Create a prompt guiding the LLM through the labeling task, and include labeled examples when needed.
Invoke LLM API: Send prompts to the LLM via API for large-scale annotation. Ensure prompts fit within the LLM’s token limits.
Postprocessing: Parse the LLM’s output, extract labels, and map them to your schema. This step can be challenging due to potential noise in free text outputs.
By following these steps, you can use LLMs to reduce reliance on human annotators while maintaining high accuracy and objectivity.