


AI Open-Source Model Paper Weekly Report (07/01-07/05)
Top AI Innovations of the Week: From Apple's 4M-21 to Microsoft's Phi-3

I want to share some interesting AI open-source models from last week.
Project: 4M-21

4M-21 is an open-source multimodal, multitask vision model from Apple. It significantly enhances existing models by training on large multimodal datasets and text corpora. The model can handle 21 types of data, including RGB images, geometric information, semantic data, edge features, feature maps, metadata, and text. It has been scaled up to 3 billion parameters, and both the model and training code are open-sourced.
Project: LLM Compiler
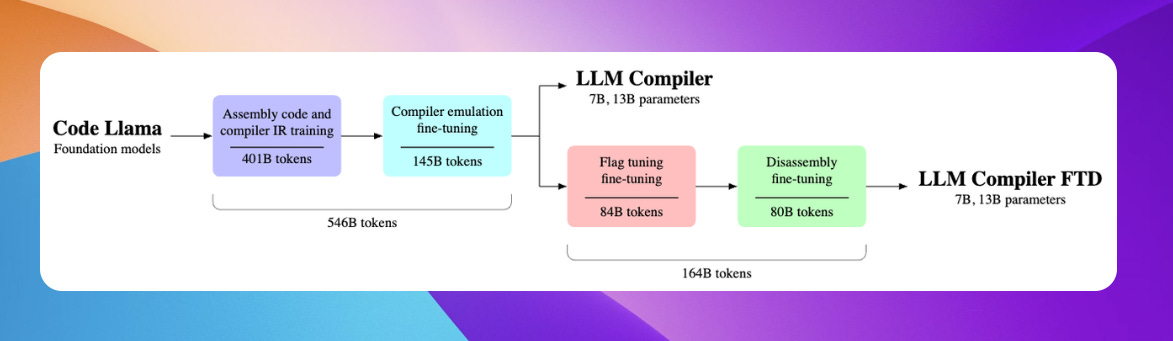
Meta's Large Language Model Compiler (LLM Compiler) is designed to optimize code and revolutionize compiler design. It is available in 7B and 13B versions. The LLM Compiler shows up to 77% optimization potential in automatic tuning, significantly reducing compilation time and improving code efficiency. Its disassembly capabilities are also excellent, with a round-trip success rate of 45%.
Project: Arcee Spark

Arcee Spark is a powerful 7B parameter language model. It is based on Qwen2 and has undergone fine-tuning on 1.8 million samples, merging with Qwen2-7B-Instruct using Arcee's mergekit, and further refined with Direct Preference Optimization (DPO). The model achieved the highest score in its category on MT-Bench and outperformed GPT-3.5 on many tasks.
Project: EvTexture

EvTexture focuses on video super-resolution using event-driven texture enhancement to improve video quality. It offered an official PyTorch implementation and was presented at ICML 2024. The project supports various datasets and pre-trained models, aiming to enhance video resolution and texture details through deep learning methods.
Project: HunyuanDiT/HunyuanDiT-v1.2

HunyuanDiT released version 1.2, along with a new Hunyuan-Captioner model that generates high-quality image descriptions from multiple perspectives, including object description, object relationships, background information, and image style. HunyuanDiT is Tencent's open-source DiT image generation model, supporting bilingual input and understanding in Chinese and English. It can be used for text-to-image and as a foundation for multimodal visual generation like videos.
https://github.com/Tencent/HunyuanDiT
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Project: AuraSR
AuraSR is a GAN-based super-resolution project for enhancing generated images. It is a variant of the GigaGAN paper. The project's Torch implementation is based on the unofficial lucidrains/gigagan-pytorch repository.
https://huggingface.co/fal/AuraSR
Project: Phi-3/Phi-3 Mini

Microsoft updated the Phi-3 Mini series, improving 4K and 128K context model checkpoints. It enhanced JSON handling and significantly improved code understanding for Python, C++, Rust, and Typescript. The update also improved multi-round instruction tracking and late-stage training. The new version supports better reasoning and long-context understanding. Phi-3 is a small model that can run on mobile phones while matching the performance of larger models like Mixtral 8x7B and GPT-3.5.
https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Project: InternLM 2.5
Shanghai AI Lab released the InternLM 2.5 series, including InternLM2.5-7B, InternLM2.5-7B-Chat, and InternLM2.5-7B-Chat-1M. This model achieves the best accuracy in its class for mathematical reasoning, surpassing Llama3 and Gemma2-9B. It supports ultra-long contexts of up to a million words and excels in long-document tasks like LongBench. InternLM2.5 can gather and analyze information from hundreds of web pages, with strong capabilities in instruction understanding, tool selection, and result reflection. The new version reliably supports building complex agents and multi-round tool usage for complex tasks.
https://github.com/InternLM/InternLM
Project: Anole

Anole, from the GAIR team at Shanghai Jiao Tong University, is an open-source, autoregressive, and natively trained large multimodal model. It can generate interleaved text and images. Improved from Chameleon, Anole uses a curated dataset of about 6,000 images for fine-tuning, achieving excellent image generation and understanding without extensive training. It can create high-quality images and interleaved text content based on user prompts.
https://github.com/GAIR-NLP/anole
Project: InternLM-XComposer-2.5

InternLM-XComposer-2.5, the latest multimodal model from Shanghai AI Lab, supports long text input and output. It excels in various text and image understanding applications, reaching GPT-4V level capabilities with only a 7B LLM backend. IXC-2.5 can extend seamlessly to 96K long contexts through RoPE extrapolation. It supports high-resolution images and multi-round multi-image conversations, suitable for web creation and high-quality text-image article production.
https://github.com/InternLM/InternLM-XComposer
Project: LivePortrait
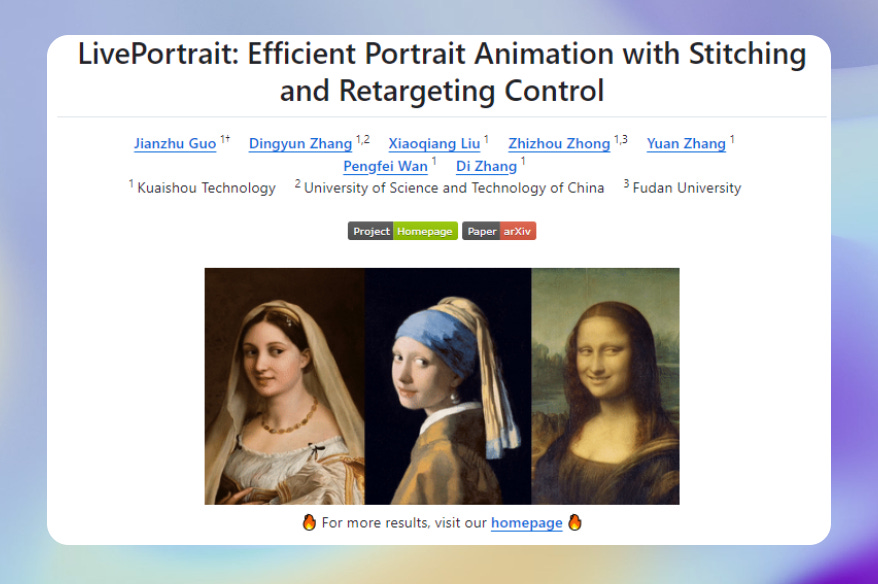
LivePortrait, from the Kuaishou team, is an efficient portrait animation method that turns static images into animated videos. Using stitching and target control techniques, LivePortrait animates static portraits. It achieves precise lip-sync and controls eye and mouth movements, making animations more vivid and natural.
https://github.com/KwaiVGI/LivePortrait
LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control