


Alibaba's Qwen-2 Tops Global Open-Source AI Model Rankings, China Takes Lead
Industry Experts Recognize China's Competitive Edge in Open-Source AI


On June 27, Hugging Face CEO Clem announced that Alibaba's Qwen2-72B model topped the open-source AI leaderboard.

They used 300 H100 GPUs to test over 100 major open-source models like Qwen2, Llama-3, Mixtral, and Phi-3 on benchmarks including BBH, MUSR, MMLU-PRO, and GPQA.
This new evaluation was done because developers were too focused on rankings and using test data in training. The old tests were also too easy, so they made it harder to truly test the models.
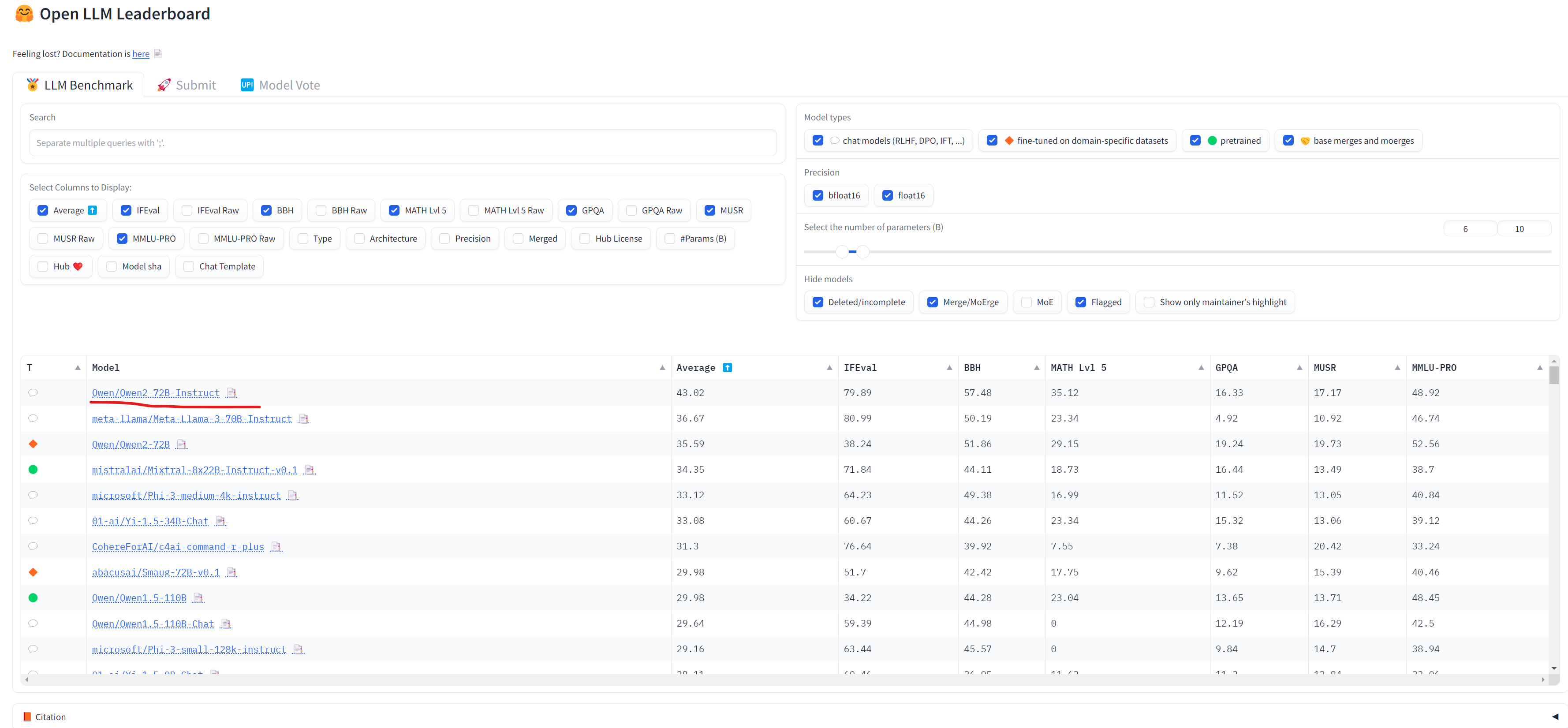
Results show Alibaba's Qwen-2 72B beat Meta's Llama-3 and Mistral AI's Mixtral, putting China in the lead for open-source AI.
The top 10 rankings are:
1. Qwen2-72B-Instruct (Alibaba)
2. Llama-3-70B-Instruct (Meta)
3. Qwen2-72B (Alibaba)
4. Mixtral-8x22B-Instruct (Mistral AI)
5. Phi-3-Medium-4K 14B (Microsoft)
6. Yi-1.5-34B-Chat (01.AI)
7. Command R+ 104B (Cohere)
8. Smaug-72B-v0.1 (NVIDIA)
9-10. Qwen1.5 base and chat versions (Alibaba)
This shows China's strong position in open-source AI. StabilityAI's research director Tanishq said China is very competitive in this field, with many well-known models besides Qwen2.
I said it's laughable to think China is behind in open-source AI. Instead, they're leading.
Qwen-2's high performance surprised many. Some hope Meta will release new models to compete.

In other tests like ElyzaTasks100, Qwen2-72B-Instruct was the top open-source model, only behind GPT-4 and ahead of Gemini 1.5 Pro.

Qwen2-72B-Instruct also competes well with closed-source models from OpenAI and Anthropic. It's the only Chinese model in the U.S. top 10.

Many hope Alibaba will keep improving and release more high-performance open-source models to benefit everyone.
https://huggingface.co/spaces/Qwen/Qwen2-72B-Instruct
https://huggingface.co/Qwen/Qwen2-72B-Instruct
Qwen-2 Features
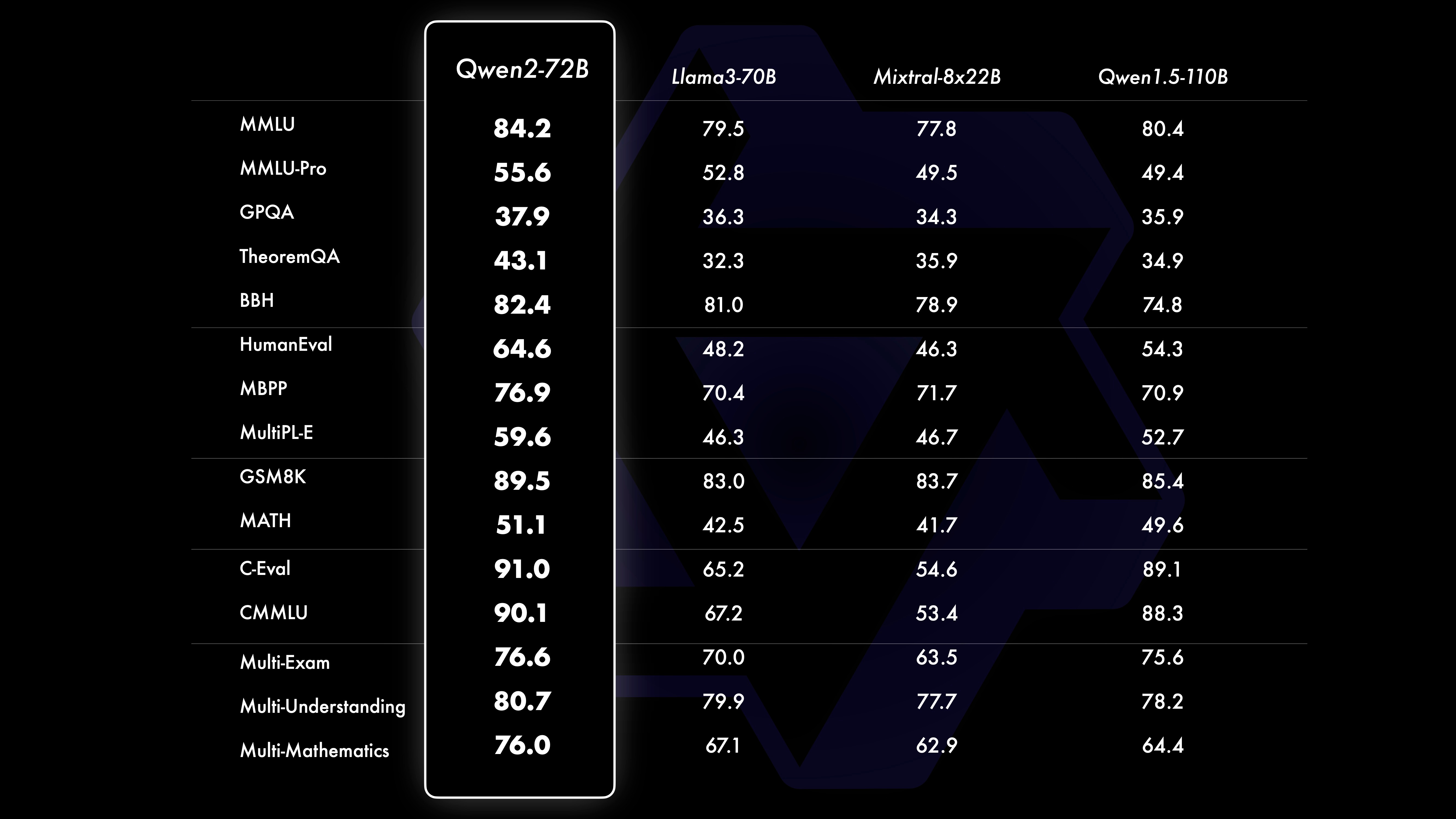
All Qwen2 models now use GQA (Grouped-Query Attention). This speeds up inference and uses less memory. For smaller models, they use Tie Embedding to share parameters between input and output layers. This increases the ratio of non-embedding parameters.
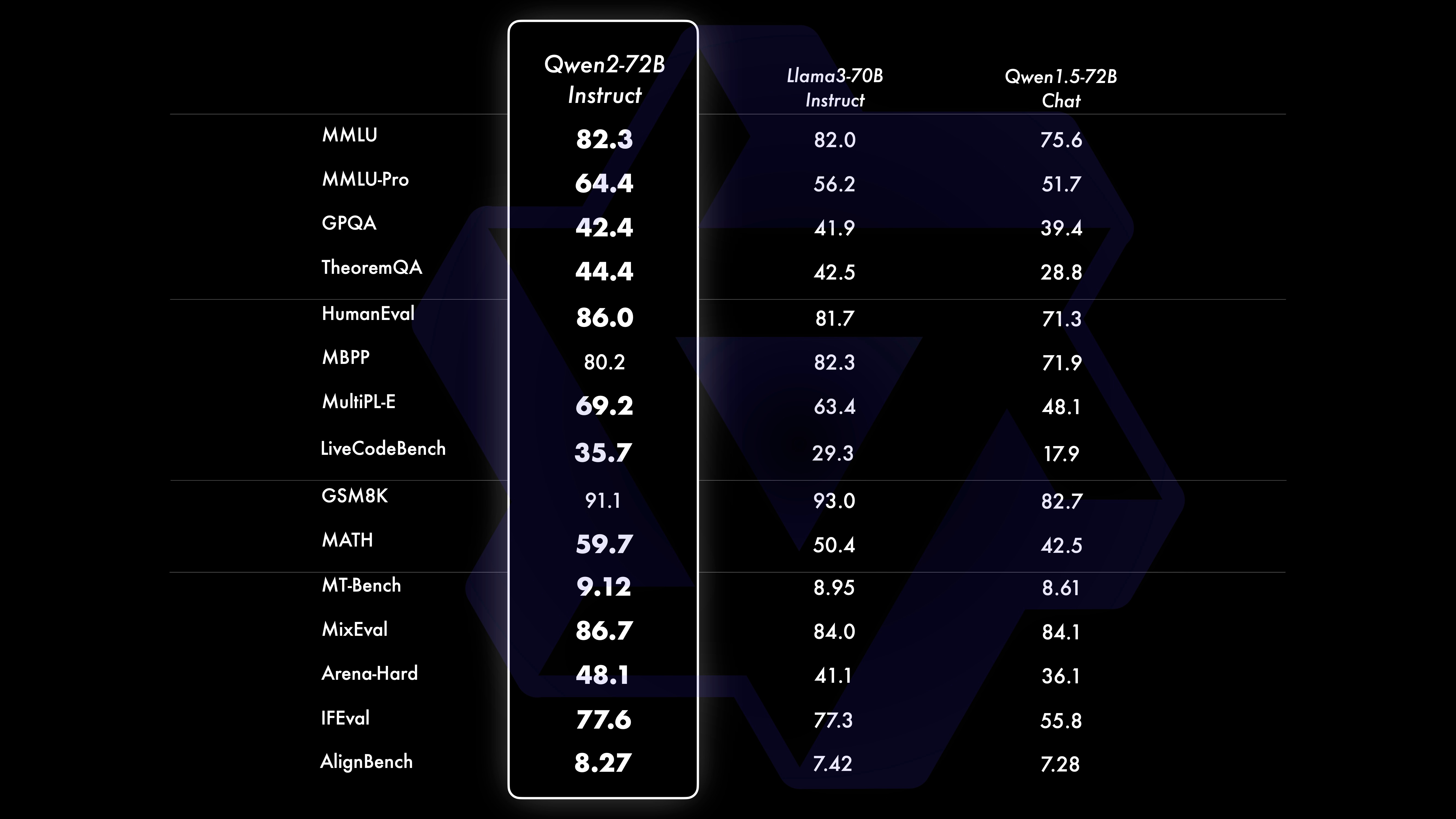
All pre-trained models were trained on 32K tokens. They work well even with 128K tokens in PPL tests. For instruction-tuned models, they also tested long-sequence understanding. The table shows the maximum context length for each model based on real tests. Using methods like YARN, Qwen2-7B-Instruct, and Qwen2-72B-Instruct can handle up to 128K tokens.
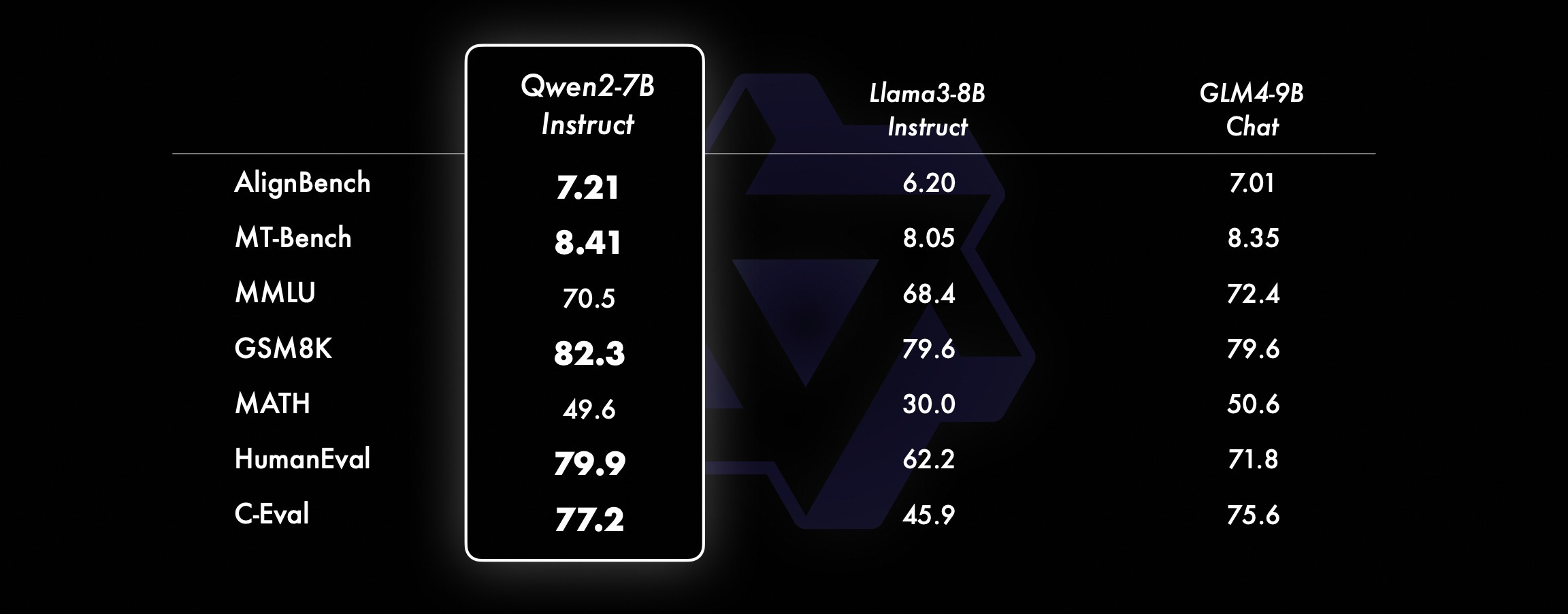
The team worked hard to improve multilingual abilities. They enhanced 27 languages besides Chinese and English. They also fixed code-switching problems, making unexpected language changes less likely. Tests show that Qwen2 models are much better at handling language switches.
