


Ali's "Trackable Version of Sora": Bid Farewell to "Gacha" and Make Video Generation More Physically Accurate
Explore Tora, a trajectory-based video generation model that excels in creating smooth, high-fidelity videos with precise control over motion and resolution.


Currently, diffusion models can generate diverse and high-quality images or videos. Previously, video diffusion models using the U-Net architecture focused on synthesizing videos of limited duration (usually around two seconds) with fixed resolution and aspect ratio.
Sora overcame these limitations with the Diffusion Transformer (DiT) architecture. It excels at creating high-quality videos ranging from 10 to 60 seconds. Sora is notable for generating videos of varying resolutions and aspect ratios while adhering to physical laws.
Sora showcases the potential of the DiT architecture. However, transformer-based diffusion models have not been fully explored for generating controllable motion videos.
To address this, researchers from Alibaba introduced Tora, the first trajectory-based DiT architecture. Tora integrates text, visual, and trajectory conditions to generate videos.

Tora’s design aligns seamlessly with DiT’s scalability, allowing precise control over video duration, aspect ratio, and resolution.
Extensive experiments show Tora excels in achieving high motion fidelity and accurately simulating physical movements.
An old wooden sailboat glides smoothly along a set path on a misty river, surrounded by dense green forests.

A crucian carp swims gracefully over the red rocky surface of Mars, with its trajectory to the left and Mars’ to the right.

Hot air balloons rise into the night sky along different paths, one on a slanted line, the other on a curved route.

Two cute kittens walk side by side on a serene golden beach.

Bubbles float gently along paths among blooming wildflowers.

Maple leaves flutter on a clear lake, reflecting the autumn forest.

A mountain waterfall cascades down, with the movements of the subject and background following different paths.

Comparing Tora with other methods, Tora produces smoother videos with better trajectory adherence and no object deformation, resulting in higher fidelity.


Method Introduction
Tora uses OpenSora as its base DiT model, including a Trajectory Extractor (TE), Spatial-Temporal DiT (ST-DiT), and a Motion-Guidance Fuser (MGF).
TE encodes arbitrary trajectories into hierarchical spatial-temporal motion patches using a 3D video compression network.
MGF integrates motion patches into DiT blocks to generate consistent videos following the trajectories. Figure 3 outlines Tora’s workflow.
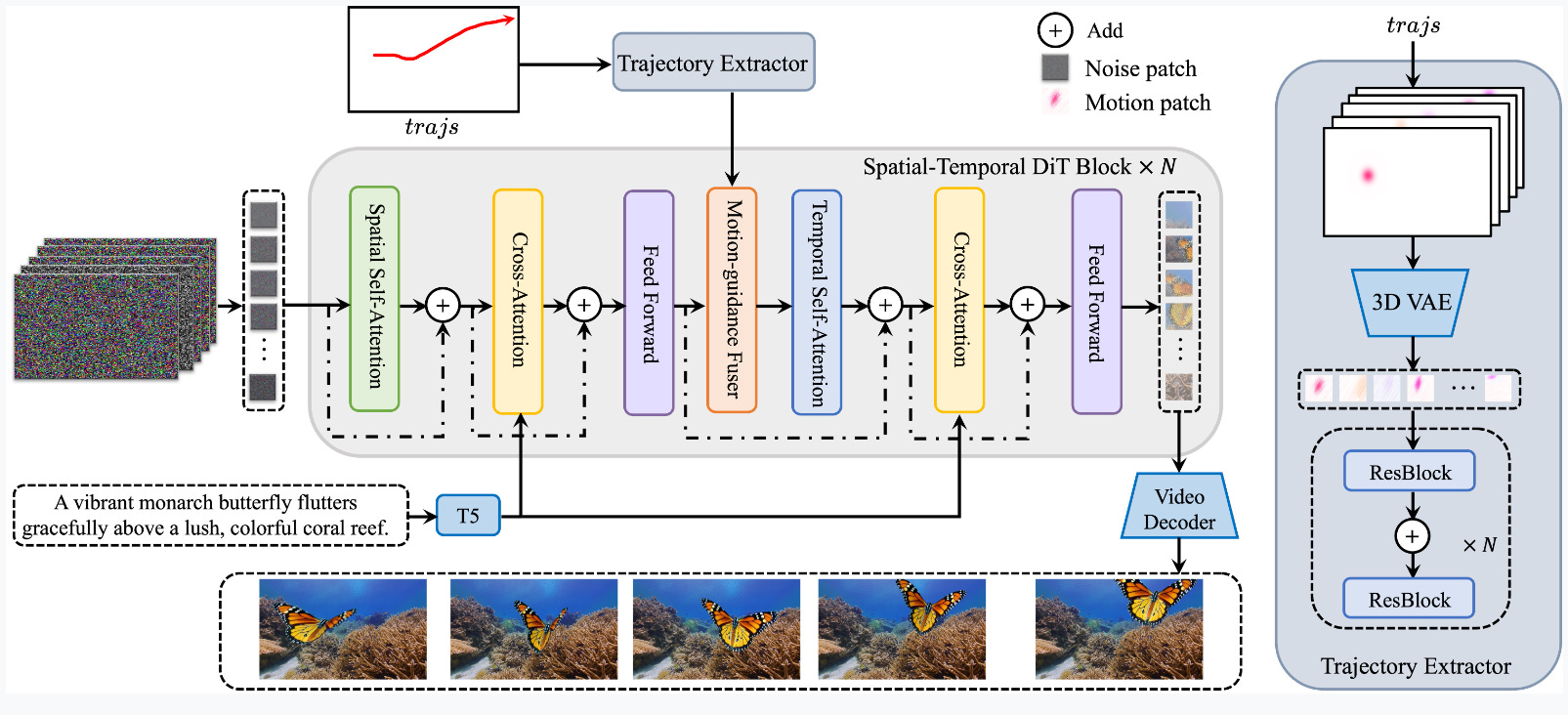
Spatial-Temporal DiT (ST-DiT)
The ST-DiT architecture has two types of blocks: Spatial DiT Block (S-DiT-B) and Temporal DiT Block (T-DiT-B), arranged alternately.
S-DiT-B includes two attention layers performing spatial self-attention (SSA) and cross-attention sequentially, followed by a point-wise feed-forward layer to connect adjacent T-DiT-B blocks.
T-DiT-B modifies this structure by replacing SSA with temporal self-attention (TSA), maintaining architectural consistency. In each block, inputs are normalized and connected back to the block’s output via skip connections.
By handling variable-length sequences, denoising ST-DiT can process videos of varying durations.
Trajectory Extractor
Trajectories are a user-friendly method to control video motion. DiT models use video autoencoders and patching processes to convert videos into patches.
Each patch spans multiple frames, making direct frame-to-frame offset unsuitable.
To solve this, TE converts trajectories into motion patches, placing them in the same latent space as video patches.
Motion-Guidance Fuser
To combine DiT-based video generation with trajectories, three fusion architecture variants are explored to inject motion patches into each ST-DiT block, as shown in Figure 4.

Experimental Results
Researchers trained Tora using OpenSora v1.2 weights.
Training videos had resolutions ranging from 144p to 720p.
To balance training FLOPs and memory requirements for different resolutions and frame numbers, they adjusted the batch size from 1 to 25.
For the training setup, they used 4 NVIDIA A100 GPUs and the Adam optimizer with a learning rate of 2 × 10^−5.
Tora was compared with popular motion-guided video generation methods.
Three evaluation settings were used: 16, 64, and 128 frames, all at 512×512 resolution.
As shown in Table 1, MotionCtrl and DragNUWA aligned better with the provided trajectories in the common 16-frame setting but were still weaker than Tora.
With more frames, U-Net methods showed noticeable deviations in some frames, leading to deformation, motion blur, or object disappearance in subsequent sequences.

In contrast, Tora, with its integrated Transformer scaling capability, remained robust to frame changes.
Tora produced smoother motions that better matched the physical world.
In the 128-frame test, Tora's trajectory accuracy was 3 to 5 times better than other methods, showing superior motion control.
Figure 5 analyzes trajectory errors for different resolutions and durations.
Unlike U-Net, which showed significant trajectory errors over time, Tora's errors increased gradually.
This is similar to the DiT model, where video quality declines over time. Tora maintained effective trajectory control for longer periods.
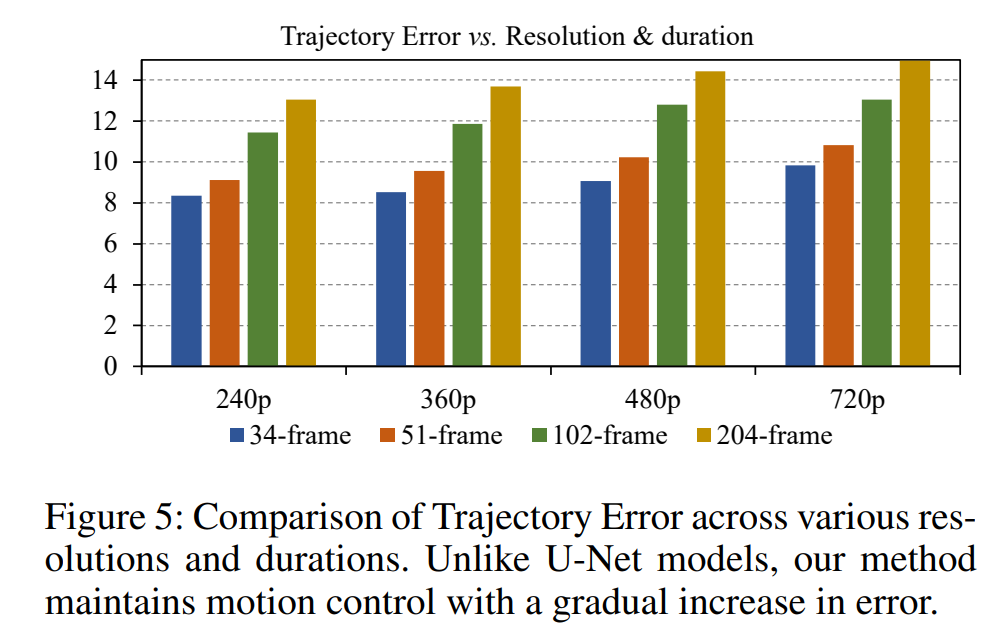
Figure 6 compares Tora with mainstream motion control methods. In scenes with two people moving together, all methods generated relatively accurate motion trajectories.
However, Tora had better visual quality due to using longer sequence frames, resulting in smoother motion and more realistic background rendering.
In the bicycle scene created by Tora, the person's legs showed realistic pedaling, whereas DragNUWA's legs floated almost horizontally, defying physical realism.
Also, both DragNUWA and MotionCtrl showed severe motion blur at the end of the video.
In another scene with lanterns, DragNUWA had severe deformations with the trajectory's up-and-down movement.
MotionCtrl's trajectory was relatively accurate but did not match the description of the two lanterns.
Tora strictly followed the trajectory, minimized object deformation, and ensured higher fidelity in action representation.

https://arxiv.org/pdf/2407.21705

