


Andrej Karpathy: The Myth of Magical AI Models—Just a Poor Imitation of Human Labels
Explore Andrej Karpathy's critique of AI models, RLHF limitations, and the future of reward mechanisms like Rule-Based Rewards (RBR) for LLMs.


Is It Time to Explore New Approaches?
How much “intelligence” is truly present in large language models’ (LLMs) responses to human conversations?
This Friday, Andrej Karpathy, a renowned AI scholar, founding member of OpenAI, and former Senior Director of AI at Tesla sparked widespread discussion by stating, "People exaggerate the idea of 'asking something from artificial intelligence.'"
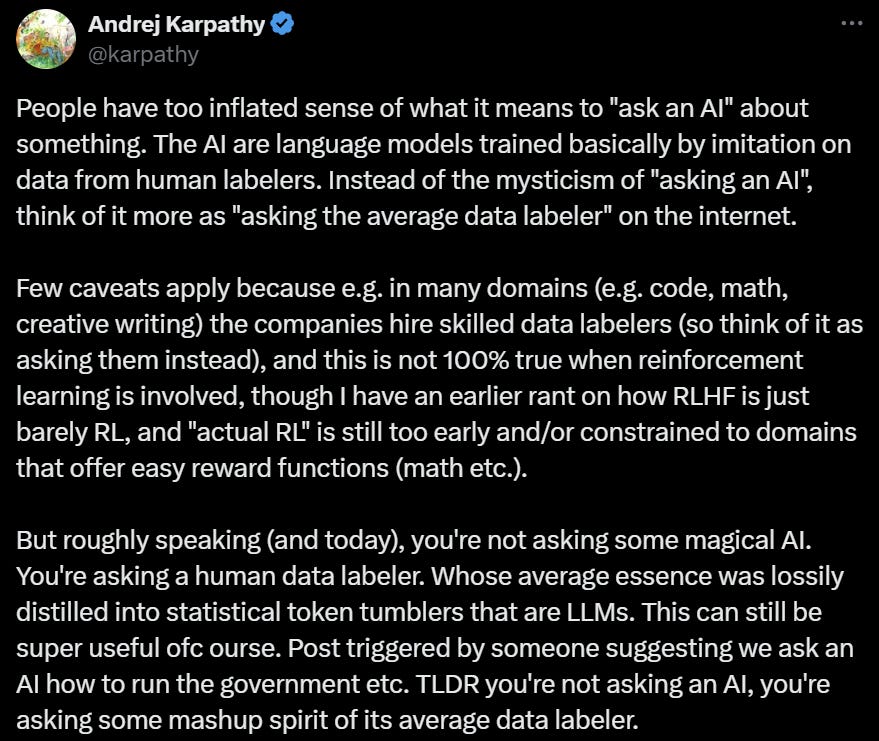
Karpathy explained that AI is essentially trained on labeled datasets to mimic human annotations. Therefore, instead of seeing conversations as “asking AI” in a mystical sense, one should view it more as “asking the average internet annotator.”
For instance, when you inquire about "the top 10 attractions in Amsterdam," some hired annotators may have encountered a similar question at some point. They likely spent 20 minutes researching on Google to compile a list of 10 attractions, which then became the “correct” answer the AI was trained to produce.
If the exact question isn’t included in the fine-tuned training set, neural networks rely on knowledge gleaned from pre-training (language modeling on internet documents) to make estimates.
When a commenter noted that "RLHF (Reinforcement Learning from Human Feedback) can create results beyond human capabilities," Karpathy responded: "RLHF is still RL based on human feedback, so I wouldn’t put it that way."
