


Apple Open-Sources the "Swiss Army Knife" of Vision Models, Capable of Dozens of Tasks
Discover How 4M-21 Revolutionizes AI with Its Versatile Multimodal Capabilities


Apple and researchers from EPFL have jointly open-sourced a large-scale multimodal vision model called 4M-21.
Most large models are optimized for specific tasks or data types. This specialization ensures high performance in specific areas but limits their versatility and flexibility.
For example, the open-source model Stable Diffusion is only for text-to-image generation, and even multimodal models like Gemini can only create and interpret images.
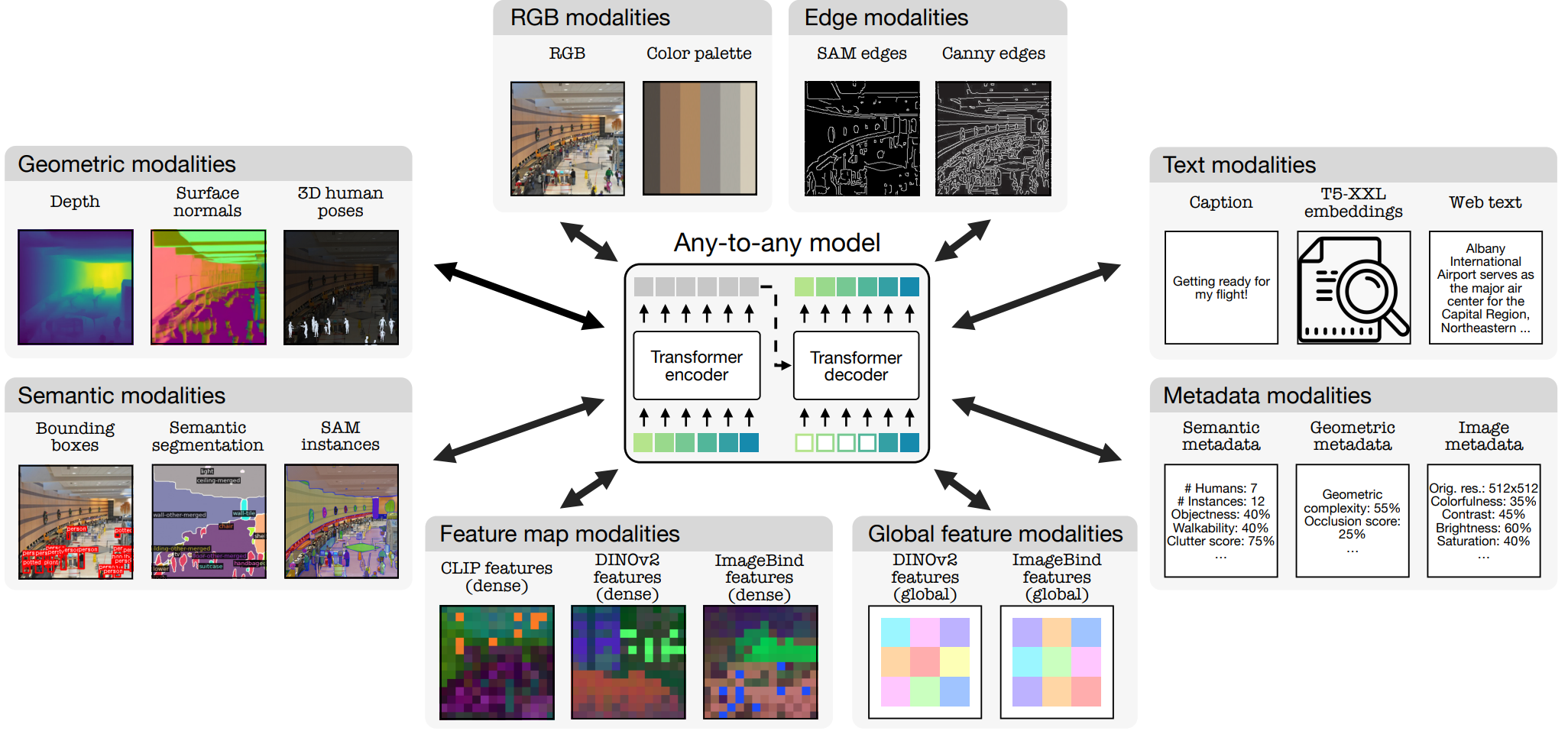
In contrast, 4M-21, with only 3 billion parameters, can perform dozens of functions, including image classification, object detection, semantic segmentation, instance segmentation, depth estimation, and surface normal estimation. It's like a "Swiss Army knife" for vision models with its comprehensive capabilities.
The key technology behind 4M-21's wide range of functions is the "discrete tokens" conversion technique. Simply put, it converts various types of data into a unified format of token sequences.
Whether it's image data, neural network feature maps, vectors, structured data (instance segmentation or human poses), or text data, all can be transformed into a format the model can understand.
This not only simplifies the model's training but also maps different types of data into a shared, easy-to-process representation space, laying the foundation for multimodal learning and processing.

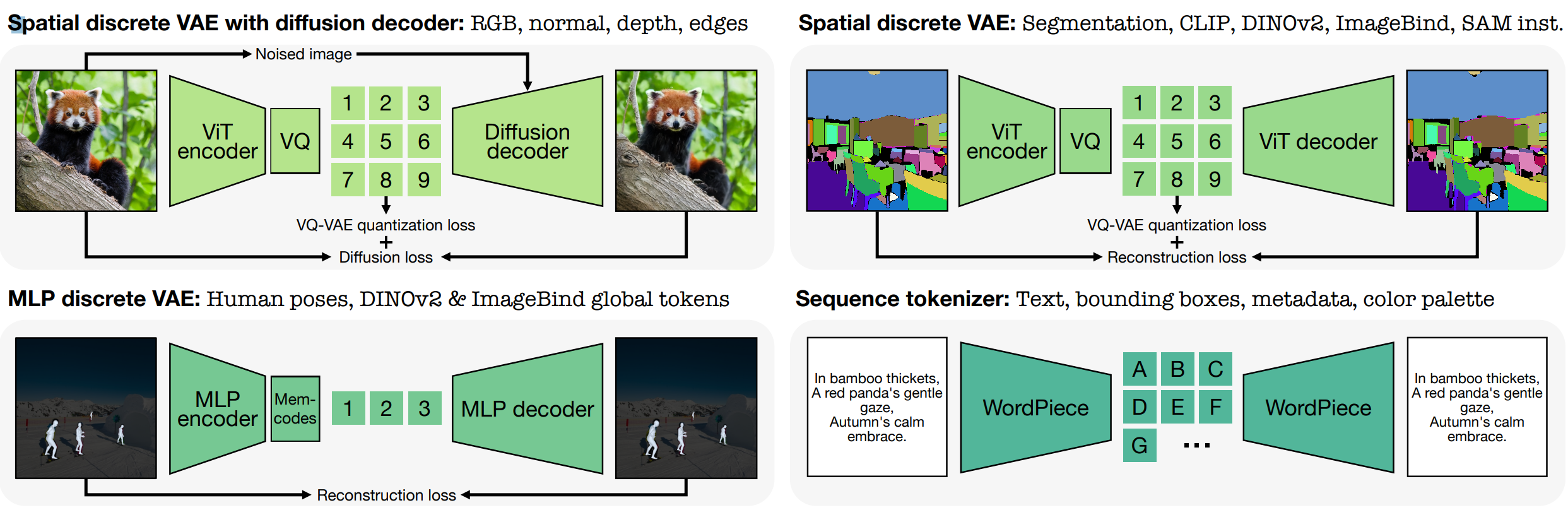
For image data, like edge detection maps or feature maps, researchers used a Vision Transformer-based variational quantization autoencoder to create a fixed-size grid of tokens.
For tasks needing high-fidelity reconstruction, like RGB images, a diffusion decoder is used to enhance visual details.
For non-spatial modalities, such as global embeddings or parameterized human poses, Bottleneck MLP and Memcodes quantization methods compress them into a small number of discrete tokens.
Text, bounding boxes, color palettes, or metadata sequences are encoded into text tokens using a WordPiece tokenizer, with special shared tokens indicating their type and value.
During the training phase, 4M-21 uses masked modeling for multimodal learning. It randomly masks parts of the input token sequences, and then predicts the masked tokens based on the remaining ones.
This method forces the model to learn the statistical structure and underlying relationships of the input data, capturing the commonality and interaction between different modalities.
Additionally, masked modeling enhances the model's generalization ability and improves the accuracy of generation tasks by iteratively predicting the missing tokens.

Whether using autoregressive (predicting one by one) or step-by-step decoding (gradually revealing masked parts), the model can generate coherent output sequences. This includes generating text, image features, or data in other modalities, thus supporting multimodal processing.
Researchers comprehensively evaluated 4M-21 on platforms like image classification, object detection, semantic segmentation, instance segmentation, depth estimation, surface normal estimation, and 3D human pose estimation.
The results showed that 4M-21's multimodal processing abilities rival the current state-of-the-art models. For example, the COCO dataset, excelled in semantic and instance segmentation tasks, accurately identifying and distinguishing multiple objects in images.
It also achieved significant results in the 3D human pose estimation task on the 3DPW dataset, precisely capturing human pose variations.

Going Open Source is always a BIG win in my view!