


Building a PDF-Based RAG System with Image Recognition (Development of Large Model Applications 10)
Learn how to integrate GPT-4V and text embeddings for advanced content retrieval and generation.

Hello everyone, welcome to the "Development of Large Model Applications" column.
Order Management Using OpenAI Assistants' Functions(Development of large model applications 2)
Thread and Run State Analysis in OpenAI Assistants(Development of large model applications 3)
Using Code Interpreter in Assistants for Data Analysis(Development of large model applications 4)
5 Essential Prompt Engineering Tips for AI Model Mastery(Development of large model applications 6)
5 Frameworks to Guide Better Reasoning in Models (Development of Large Model Applications 7)
Using Large Models for Natural Language SQL Queries(Development of Large Model Applications 9)

In the first two lessons, we explored how to use large language models like ChatGPT to automatically generate Python unit tests and SQL queries through a carefully designed multi-step prompting process.
These examples vividly demonstrate the power of prompt engineering and the vast potential of language models in software development.
Now, we turn our attention to a more challenging task: building an advanced Retrieval-Augmented Generation (RAG) system that can read "figures" from PDF documents.
RAG is a system that combines knowledge retrieval with language generation. It first retrieves relevant information from an external knowledge base and then uses this information as additional input to help the model generate more accurate and relevant output.
RAG can continuously update its data sources, adapting to new information and trends, ensuring the relevance and accuracy of its responses.
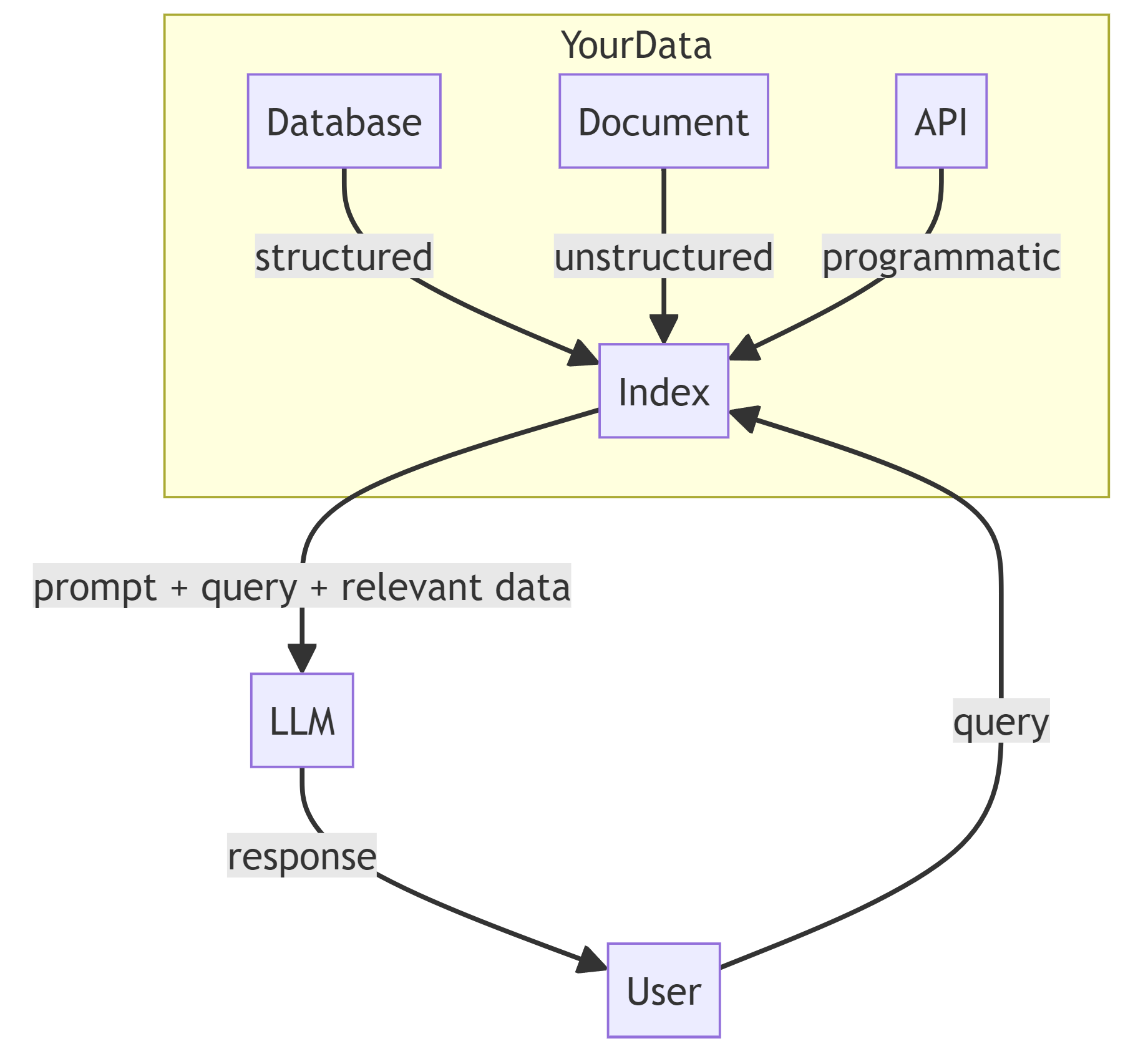
RAG has been a hot topic this year, regarded by many as the first step in the practical application of large models. From my project experience, this is indeed the case.
This technology is highly regarded and seen as a crucial direction for the implementation of large models for several reasons:
Knowledge Enhancement: RAG systems integrate relevant information from external knowledge bases during generation, allowing the model to utilize a broader and more accurate knowledge base. This greatly enhances the model's ability to handle knowledge-intensive tasks like Q&A, dialogue, and document generation.
Explainability: Traditional end-to-end generation models are often seen as black boxes, making it hard to explain their output. RAG systems can clearly indicate the external knowledge sources referenced in their output, enhancing the model's explainability and credibility, which is important for applications requiring traceable and verifiable results.
Scalability: The knowledge base of an RAG system is independent of model training, meaning we can flexibly expand and update the knowledge without retraining the model. This decoupling design makes it easier for RAG systems to adapt to different fields and scales of application.
Data Efficiency: Compared to training a large model from scratch, RAG systems can more effectively use external knowledge to achieve good results with smaller data scales. This means lower data collection and annotation costs in practice.
Technological Maturity: The technologies involved in RAG systems, such as information retrieval, semantic matching, and language generation, have made significant progress in recent years. Open-source RAG solutions like LangChain, and LlamaIndex, and features provided by OpenAI's Assistants have lowered the threshold for building RAG systems, promoting their application in the industry.