


DeepSeek Launches JanusFlow: A 1.3B Model Unifying Visual Understanding and Generation
JanusFlow unifies visual understanding and generation in a 1.3B LLM, integrating vision encoders and Rectified Flow for multimodal AI breakthroughs.

In the field of multimodal AI, methods based on pre-trained vision encoders and MLLMs (e.g., the LLaVA series) demonstrate exceptional performance in visual understanding tasks.
Meanwhile, models based on Rectified Flow (e.g., Stable Diffusion 3 and its derivatives) have achieved significant breakthroughs in visual generation.
Is it possible to unify these two simple technical paradigms into a single model?
Research from DeepSeek, Peking University, the University of Hong Kong, and Tsinghua University suggests:
Directly integrating these two architectures within an LLM framework enables the effective unification of visual understanding and generation capabilities.
Model Architecture
In simple terms, JanusFlow combines the understanding framework based on a vision encoder and LLM with the generation framework based on Rectified Flow. This integration enables end-to-end training within a single LLM.
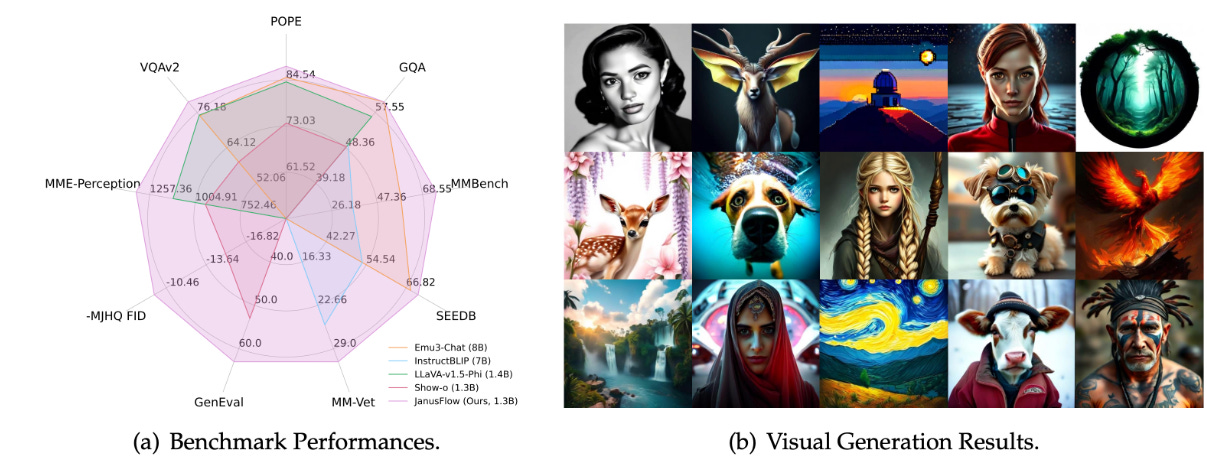
Key Design Features:
Decoupled Vision Encoders: Separate optimization of understanding and generation capabilities.
Representation Alignment: Use the understanding encoder to align features for the generation component, significantly improving RF training efficiency.
Using an LLM with 1.3B parameters, JanusFlow outperforms prior unified multimodal models of similar scale in both visual understanding and generation tasks.