


Efficient Fine-Tuning of Llama 3.1 with Unsloth in Google Colab
Optimize Llama 3.1 with Unsloth in Google Colab: Efficient fine-tuning for superior performance and customization at a lower cost.


The recently released Llama 3.1 model offers incredible performance, narrowing the gap between closed-source and open-weight models.
Instead of using general-purpose LLMs like GPT-4o and Claude 3.5, you can fine-tune Llama 3.1 for specific use cases. This approach provides better performance and customization at a lower cost.
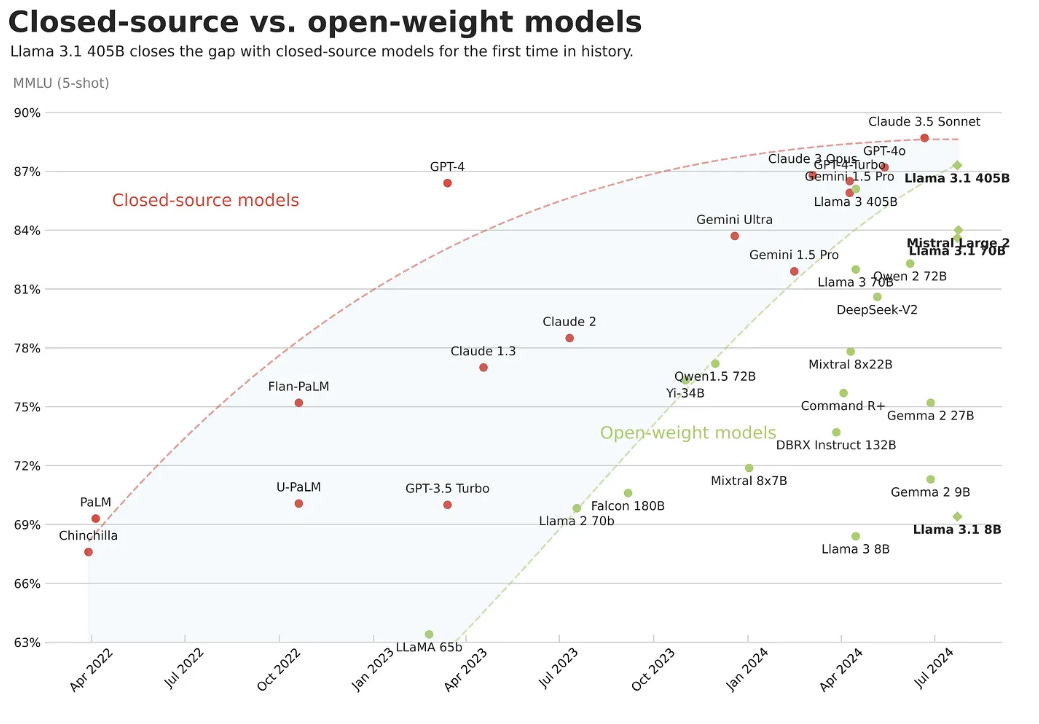
In this article, we provide a comprehensive overview of supervised fine-tuning. We'll compare it to prompt engineering to understand when it's appropriate to use. We'll also discuss key techniques, their pros and cons, and important concepts like LoRA hyperparameters, storage formats, and chat templates.
Finally, we'll implement this by fine-tuning Llama 3.1 8B in Google Colab using Unsloth for state-of-the-art optimization.