


FlashAttention3 is Here: H100 Utilization Soars to 75%
FlashAttention-3 reaches 740 TFLOPS with 75% H100 utilization. Achieves up to 1.2 PFLOPS on FP8, enhancing LLM performance, efficiency, and context handling.

740 TFLOPS! The Most Powerful FlashAttention Yet
As large language models (LLMs) become more widespread, expanding model context windows is increasingly important. However, the core of the Transformer architecture, the attention layer, has time and space complexity proportional to the square of the input sequence length, posing challenges for context window expansion.
In 2022, FlashAttention, a fast, memory-efficient attention algorithm, was introduced. It accelerates attention computation and reduces memory usage without approximation by reordering attention computation and using tiling and recomputation. This reduces memory usage from quadratic to linear.
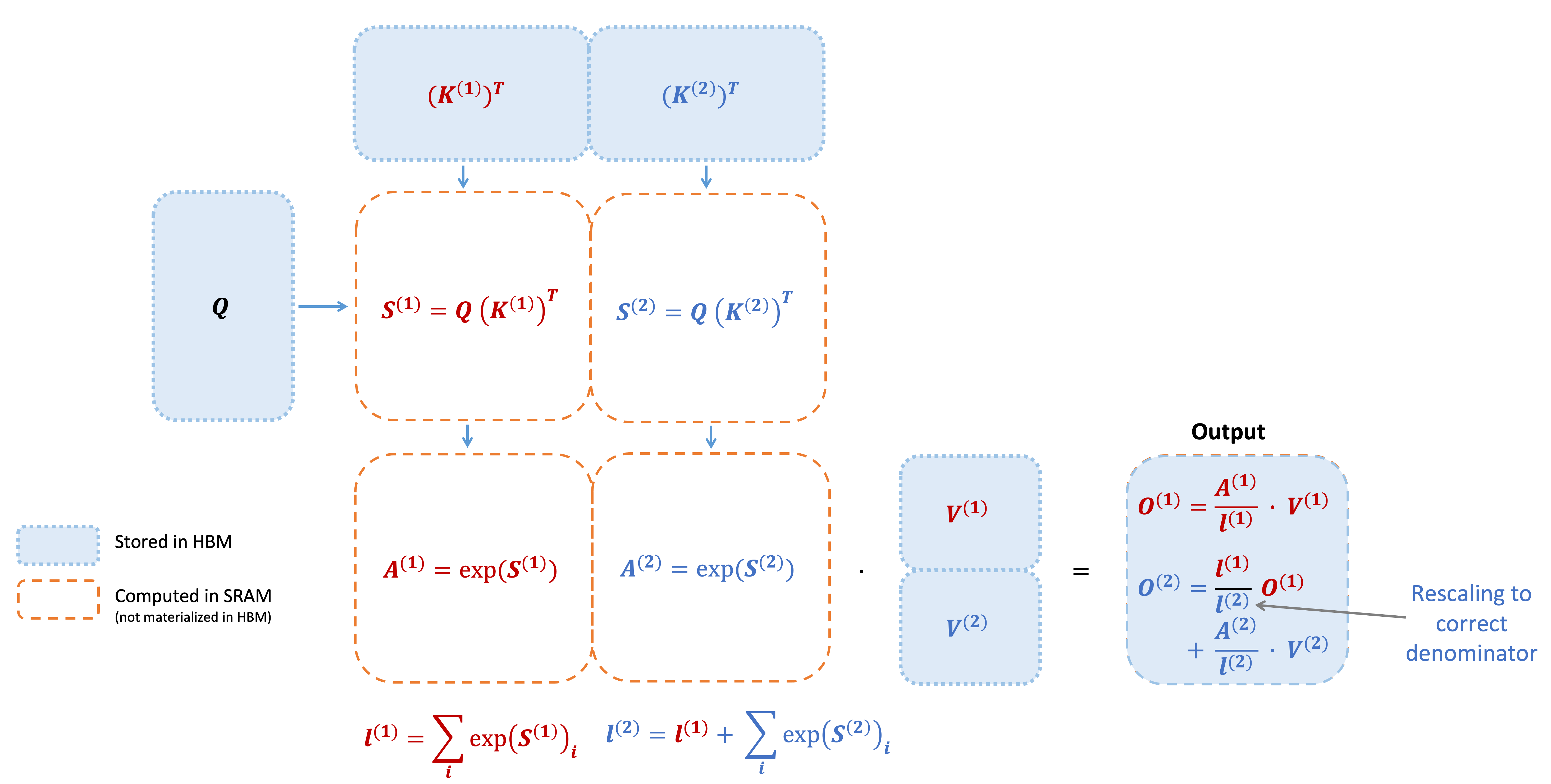
In 2023, FlashAttention-2 brought significant improvements in algorithms, parallelization, and work partitioning. Now, researchers from Meta, Nvidia, Together AI, and other institutions have announced FlashAttention-3, which uses three main techniques to accelerate Hopper GPU attention:
Overlapping computation and data movement with warp-specialization.
Interleaving block mammal and softmax operations.
Utilizing hardware support for FP8 low-precision incoherent processing.