


Huawei and Tencent Open-Source AniPortrait: Generate Talking Videos from Audio and Images
2 Key Features of AniPortrait: Revolutionizing AI-Generated Talking Videos


Huawei and Tencent researchers have jointly open-sourced an innovative video model called AniPortrait.
AniPortrait allows users to generate audio-synced videos from audio and character images. For example, it can make images of characters like Li Yunlong, Aragaki Yui, and Cai Xukun sing or talk.
This is similar to Alibaba's EMO model and Google's VLOGGER released earlier this year, but those models are closed-source.
AniPortrait's core framework has two main parts. First, AI extracts 3D facial meshes and head poses from the voice. Then, these intermediate representations are used to generate realistic portrait video sequences.
Audio2Lmk Audio Extraction Module
Audio2Lmk uses the speech recognition model wav2vec 2.0 to extract rich semantic representations from raw audio waveforms. It accurately captures subtle features like pronunciation and intonation, laying the foundation for facial motion capture.
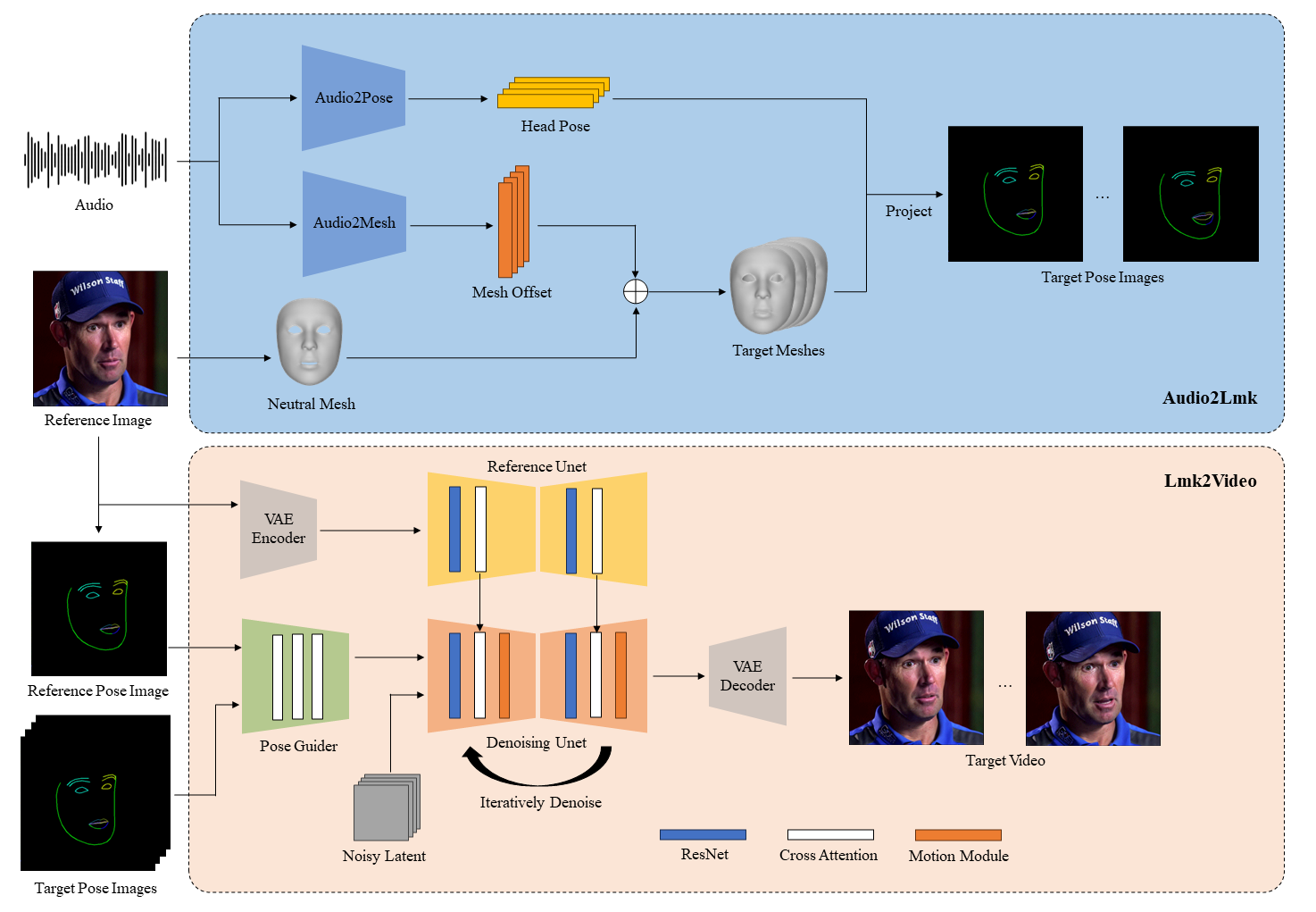
Researchers designed two parallel small networks to learn 3D facial mesh sequences and head pose sequences from the features extracted by wav2vec.
A minimalist network with only two fully connected layers handles 3D facial mesh prediction. Despite its simplicity, this design ensures efficient computation and significantly improves accuracy.
To better align head poses with the rhythm and pitch of the speech, researchers used a Transformer decoder. This captures fine-grained temporal relationships.
The input for the decoder is the speech features extracted by wav2vec 2.0. During decoding, the Transformer learns the intrinsic connections between the audio and head poses through self-attention and cross-attention mechanisms. It then decodes a head pose sequence that closely matches the audio rhythm.
For training, researchers used nearly an hour of high-quality actor speech from internal sources and the publicly available HDTF facial dataset. Supervised learning methods were employed to enhance the precise mapping from audio to 3D facial expressions and head poses.
Lmk2Video Video Generation Module
Lmk2Video's main function is to render the 3D facial and pose data captured by Audio2Lmk into high-resolution video.
Lmk2Video uses the AnimateAnyone model, known for generating high-quality, coherent videos based on given human pose sequences.

However, facial details are much more complex than body movements and require high precision to capture subtle mouth movements and facial muscle actions.
The original AnimateAnyone's pose-guiding module uses only a few convolutional layers, encoding the human pose data and integrating it into the early stages of the main network. This design is somewhat effective for larger body movements but struggles with facial details. Therefore, researchers modified AnimateAnyone.
They added facial key points from images as input and used attention modules to interact with target key sequences. This allows the network to better understand the connection between facial features and overall appearance, enhancing the animation's detail and consistency.
Additionally, to improve sensitivity to mouth movements, researchers used different colors to distinguish the upper and lower lips when rendering 2D key points into pose images. This helps the network more clearly perceive small-mouth details and changes.
Open-source link: https://github.com/Zejun-Yang/AniPortrait
Paper link: https://arxiv.org/abs/2403.17694
