


Llama 3 Matches GPT-4 Performance with Less Parameters
Are Large Models Too Expensive?


Meta Announces Development of Llama 3 Language Model
Meta has released two Llama 3 models: one with 8 billion parameters and another with 70 billion. They are also developing another model with 400 billion parameters.
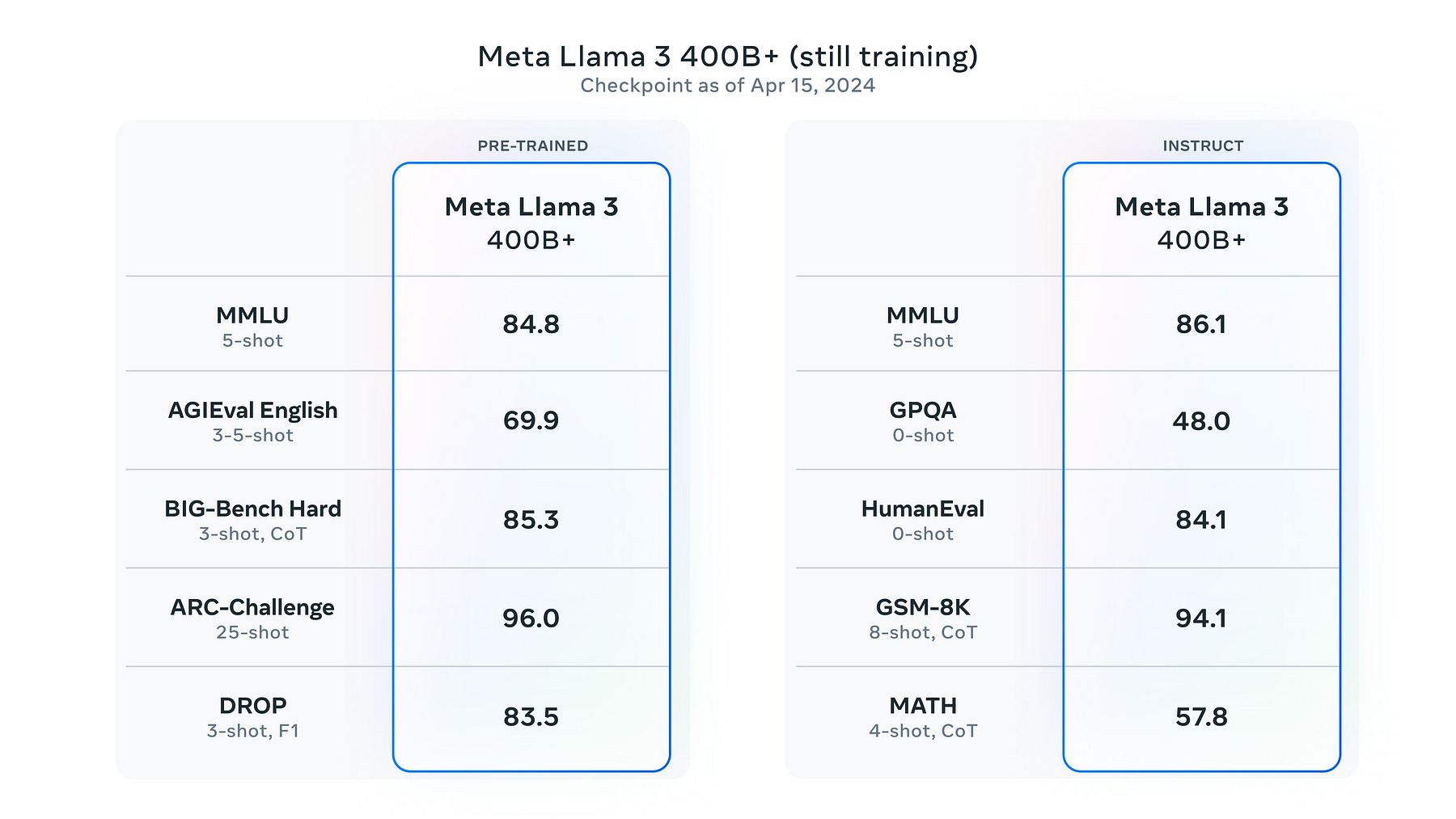
In the MMLU benchmark tests, GPT-4 scored 86.5, while Llama 3 scored 84.8, a small difference.
The MMLU test, covering natural and social sciences, demonstrates Llama 3’s broad capabilities.
As Llama 3 evolves, competition between Meta and OpenAI in language models intensifies.
Llama 3 Features
For a model with 8 billion parameters, training with 15 trillion tokens is a huge data set.
The Chinchilla model trains with 20 billion tokens for optimal cost performance.
Llama 3 uses 75 times this amount, aiming to create a strong yet compact model for simpler use and inference.
Meta found that Llama 3 didn’t learn as well as expected, even with lots of data. This means large AI language models might be 100 to 1,000 times more powerful than thought before.
Llama 3 was trained with 15 trillion tokens, far exceeding the 2 trillion used by Llama 2.
Meta made the data better. They used more code and words from over 30 languages. This helps the AI understand more.
When training Llama 3, they added more code. This makes it better at understanding things.
The model also uses a bigger vocabulary. This helps it use fewer tokens and do better on tasks.
Llama 3 got better inside too. Now all sizes use a new way to pay attention called GQA. This makes the model simpler and faster.
Lastly, Meta was meticulous about the data used to train Llama 3. They made sure it was high quality. This helps the model work well in the real world.
Synthetic Data

Synthetic data is a new research area without a top technology yet. DALLE-3 and Sora models that create data are examples of how synthetic data is used.
We should invest more in synthetic data research to stay competitive in the future.
Next year, we might need better data. Just using more data will not make models better. Big models may only improve if fake data improves in two years. This could make it hard to keep making AI tools.
Currently, there’s no proof that multimodal data greatly enhances model reasoning. Thus, it’s unwise to depend on it to improve AGI capabilities.
The future of synthetic data could go two ways:
One chance is that data gets less helpful as time goes on. This would make it hard for models to do more things. Open and closed models might start to look the same. This could be bad for companies that use closed models.
The other chance is that fake data or new tech gets much better. This would let models use data better and improve a lot. But it would need a lot of money and resources. Open models might not be able to keep up with closed ones.
These approaches highlight the diversity in AI technology development.