


Meta Releases Llama3.2 1B/3B Quantized Models: Accelerated Edge Inference, Reduced Memory Usage
Meta launches Llama3.2 quantized models with 2-4x faster inference and reduced memory usage, optimized for mobile devices.


On October 24, 2024, Meta announced the release of the first lightweight series of Llama3.2 quantized models. These models have sufficient performance and a compact size, enabling them to run on many popular mobile devices.
With the rapid development of AI technology, the demand for on-device inference is increasing, and Meta's release aims to address this pain point.
Overview
Meta's release of the two quantized Llama3.2 models brings two major improvements:
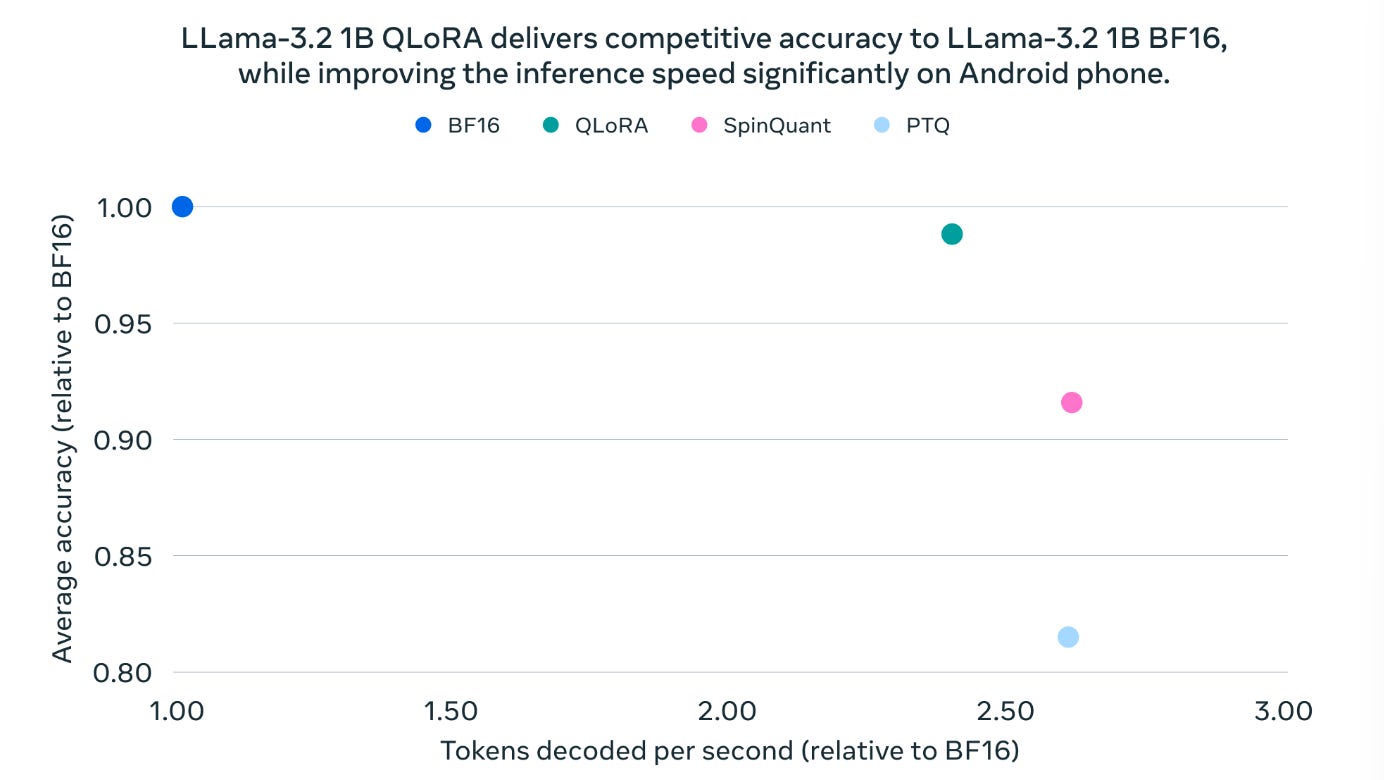
Speed Boost: The new models have 2-4 times faster inference, effectively enhancing the user-end interaction experience.
Reduced Memory Usage: Model size is reduced by 56%, and memory usage is decreased by 41%, allowing the models to run on memory-constrained devices such as mobile phones.
Quantization Techniques
To achieve these significant performance improvements, Meta introduced two key quantization techniques—Quantization-Aware Training (QAT) and SpinQuant—which played a crucial role in optimizing model size and inference performance.
Let's dive into these quantization methods and their application scenarios.