


Microsoft Open-Sources GraphRAG: Enhancing LLM Q&A, Summarization, and Reasoning
Unlocking the Power of Graph-Based RAG: A Game-Changer for AI Models


On July 3, Microsoft open-sourced GraphRAG, a graph-based Retrieval-Augmented Generation (RAG) on their official website.
To enhance the search, Q&A, summarization, and reasoning capabilities of large models, RAG has become a standard feature for well-known models like GPT-4, Qwen-2, Wenxin Yiyan, and Gemini.
Traditional RAG systems handle external data sources by converting documents to text, splitting them into fragments, and embedding them into a vector space where similar semantics are placed close together.
However, this method has limitations in handling large-scale data queries requiring global understanding, as it overly relies on local text fragment retrieval and fails to capture the complete dataset.
To address this, Microsoft enhanced RAG with "Graph" structures, constructing extensive knowledge graphs from entities like people, places, and concepts in the text. This helps large models better capture complex relationships and interactions, enhancing their generation and retrieval capabilities.
Open-source link: https://github.com/microsoft/graphrag?tab=readme-ov-file
Simple Overview of Graph RAG Architecture
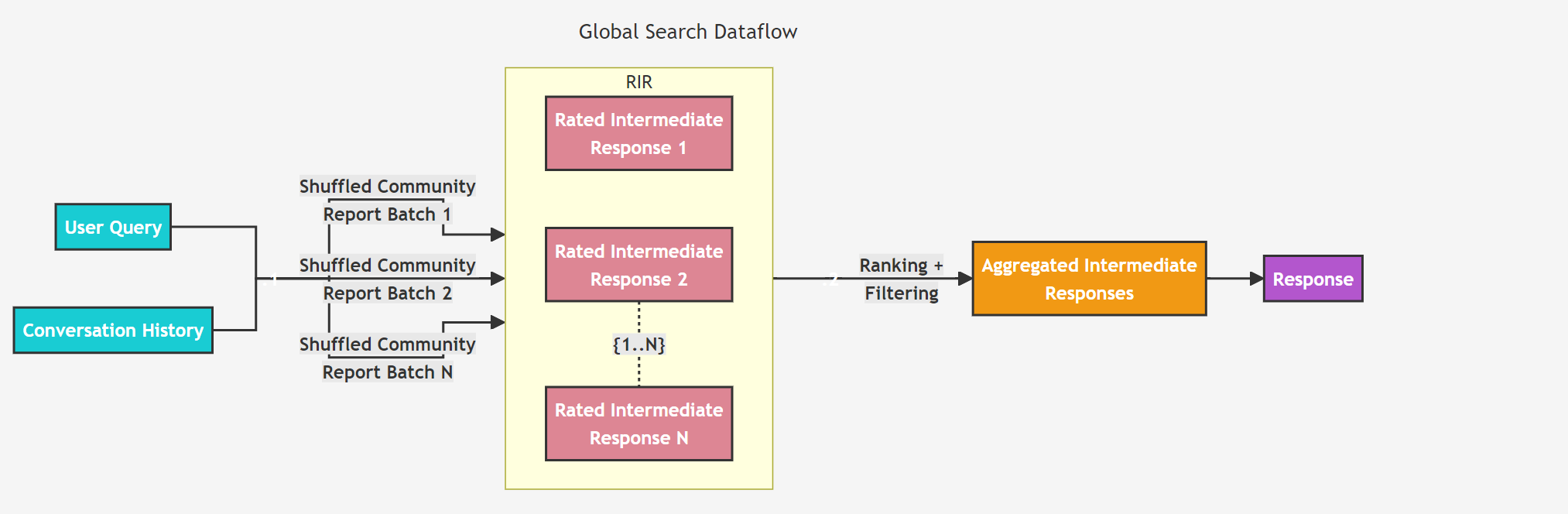
The core of Graph RAG involves a two-stage process to build graph-based text indices. First, it derives an entity knowledge graph from the source documents. Then, it pre-generates community summaries for all closely related entity groups.
The first step in Graph RAG is to split the source documents into smaller text blocks, which are then input into the large model to extract key information.

During this process, the model identifies entities in the text and the relationships between them, constructing a large entity knowledge graph that includes all significant entities and their relationships.
Simply put, this process is like breaking down a whole chicken (data) into smaller parts like legs, wings, and breast meat, while also noting the relationships between these parts for easier subsequent processing.

Next, Graph RAG uses community detection algorithms to identify modular communities within the graph. These communities consist of related nodes more tightly connected to each other than to the rest of the graph. This way, the entire graph is divided into smaller, more manageable units, each representing a specific topic or concept in the dataset.
On top of the graph-based index, Graph RAG generates community summaries, which provide a high-level understanding of specific parts of the dataset by summarizing all entities and relationships within the community.
The model then scores each answer, filtering out low-scoring ones and ranking the remaining answers. The highest-scoring answers are gradually added to a new context window until the word limit is reached.
For example, when a user asks, "How to lose weight effectively?", the system uses related community summaries to generate partial answers, which are then combined and refined to form the final answer.
Benefits of Graph RAG for Large Models
Compared to traditional RAG, Graph RAG excels in global retrieval, making it highly effective for large-scale datasets. Here are the key benefits of large models:
Extended Context Understanding: Large models are usually limited by the size of their context window, restricting their ability to understand and generate long texts. Graph RAG overcomes this by creating graph-based indices, breaking the text collection into manageable community modules, thereby extending the model's understanding and generation capabilities.
Enhanced Global Querying: Traditional RAG methods struggle with global data queries due to reliance on local text fragment retrieval. Graph RAG generates community summaries, allowing the model to extract relevant information from the entire dataset, producing more comprehensive and accurate answers.
Improved Summary Quality and Diversity: By generating community summaries in parallel and then aggregating them, Graph RAG helps large models extract information from different angles and communities, leading to richer summaries.

Optimized Compute and Resource Utilization: Efficient resource use is crucial when handling large text datasets. Graph RAG's modular processing reduces computational resource demands. Compared to traditional full-text summarization methods, Graph RAG generates high-quality summaries with significantly fewer tokens.
Enhanced Information Retrieval and Generation Synergy: By combining retrieval-enhanced and generation tasks, Graph RAG improves the accuracy and relevance of generated content.
Better Understanding of Dataset Structure: Constructing knowledge graphs and community structures helps the model understand not just the text content but also the intrinsic structure of the dataset.
Improved Handling of Complex Queries: When dealing with complex queries requiring multi-step reasoning or integrating information from multiple documents, Graph RAG enhances deeper understanding by retrieving and summarizing information from different communities. This is particularly useful for interpreting PDF, Word, and other documents.
To evaluate Graph RAG's performance, Microsoft conducted comprehensive tests on a highly complex dataset of one million tokens, covering entertainment, podcasts, business, sports, technology, and healthcare.
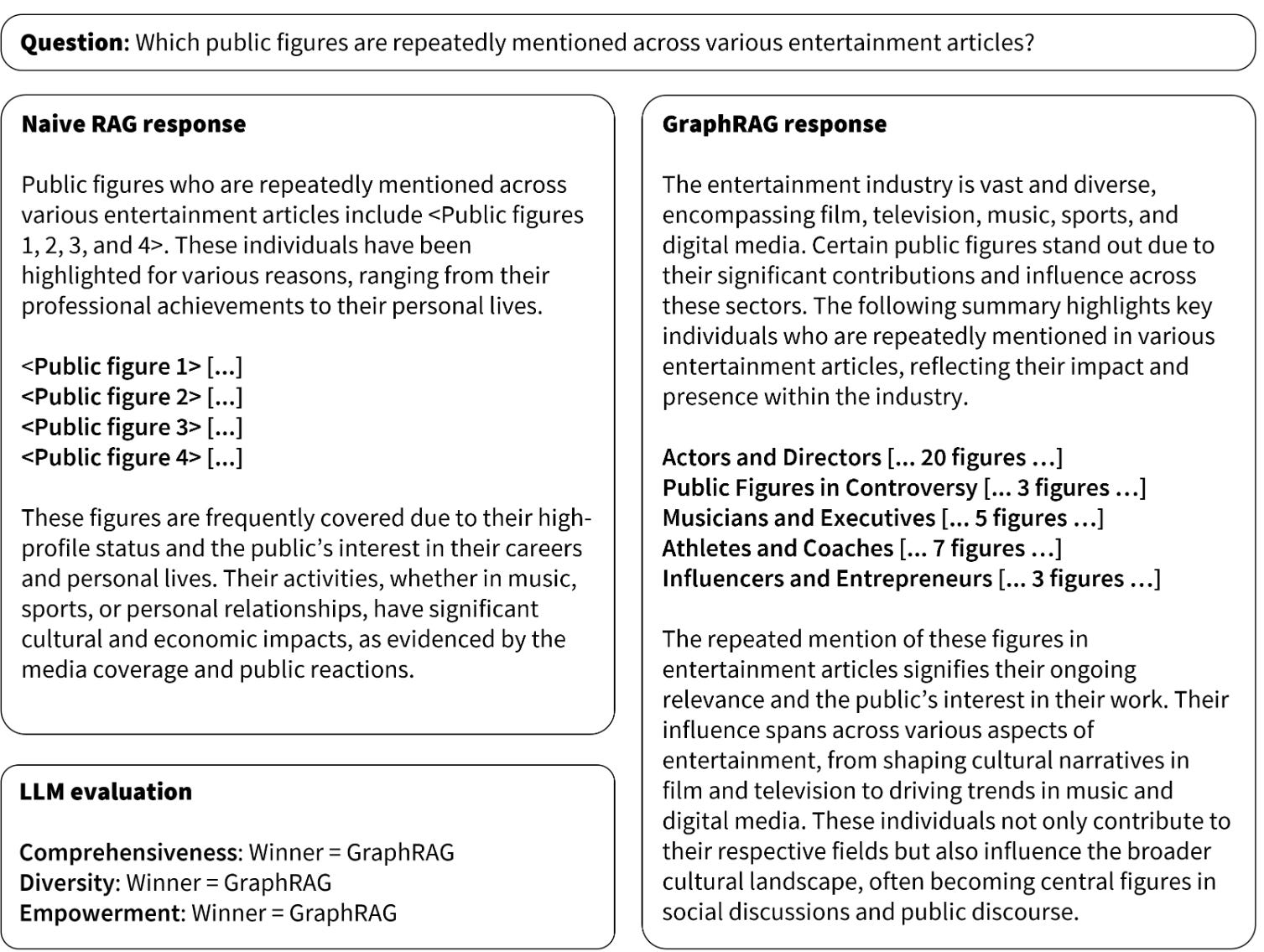
Results showed that the global retrieval method outperformed Naive RAG in comprehensiveness and diversity tests. Particularly, Graph RAG excelled in podcast transcription and news article datasets, demonstrating superior levels of detail and diversity, making it one of the best RAG methods available.
Moreover, Graph RAG's low token requirement helps developers save significant costs.

