


Microsoft Unveils Phi-4: 14B Parameters, Outperforming GPT-4o in Math and Llama 3.3 in Programming
Microsoft unveils Phi-4: a 14B-parameter model surpassing GPT-4o in math, Llama 3.3 in programming, and excelling in long-text processing with midtraining.

OpenAI and Google Keep Chasing Traffic, Microsoft Joins the Fray with the Latest Small Model Phi-4
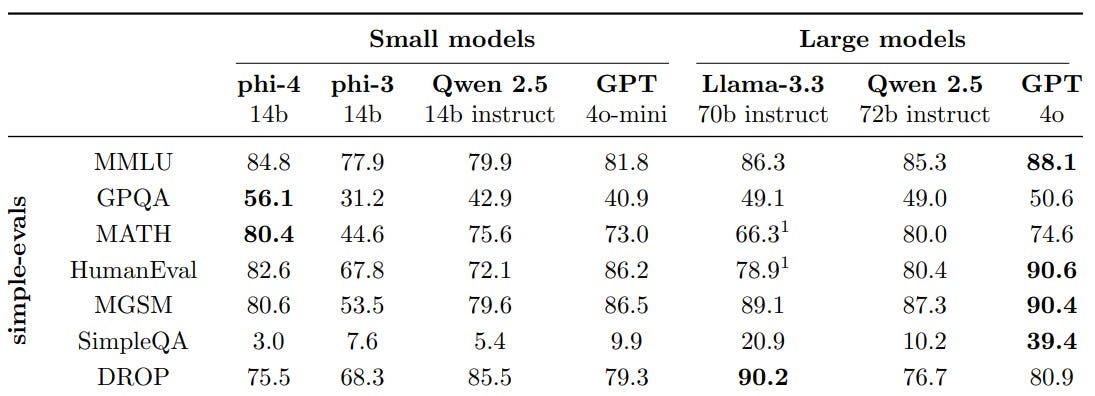
With only 14 billion parameters, Phi-4 matches the performance of large-scale models like Llama 3.3 and Qwen 2.5 (70B models) on the MMLU benchmark.

In terms of math skills, Phi-4 surpasses models like GPT-4o on the American Mathematics Competitions (AMC 10/12) with scores exceeding 90.
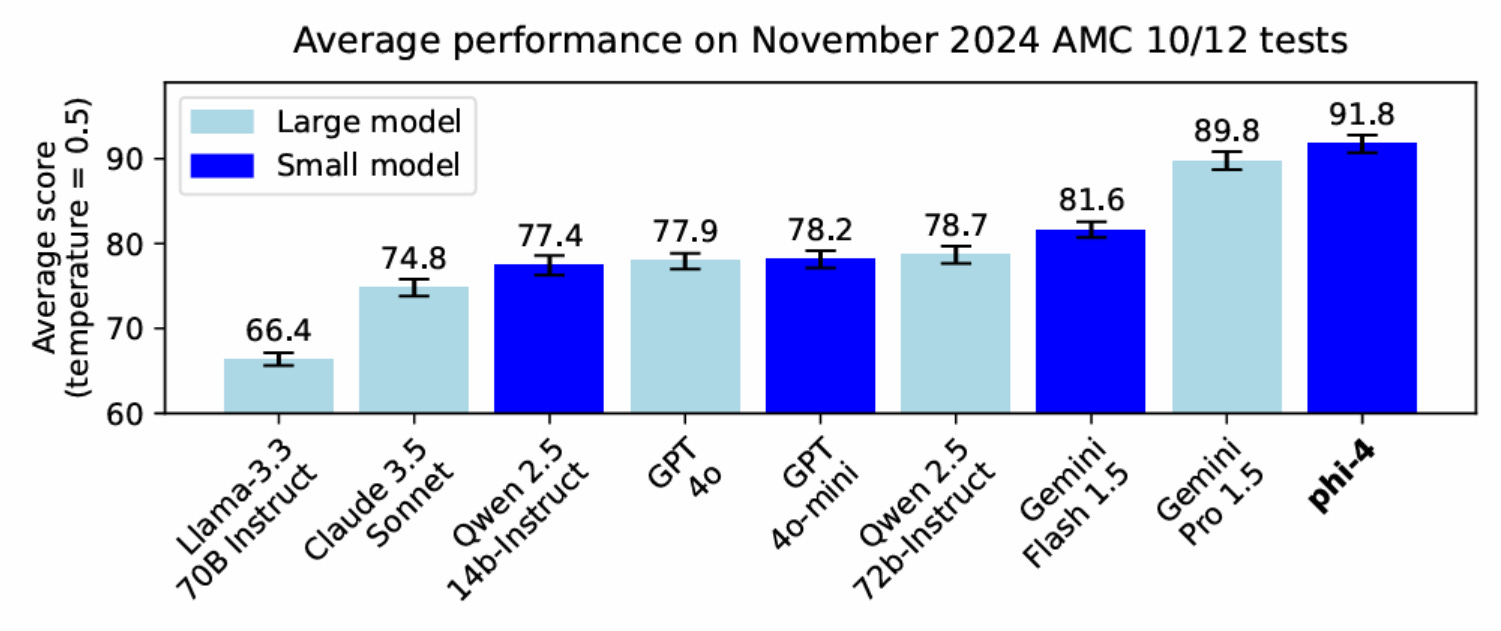
Its programming abilities also stand out, outperforming 70B models like Llama 3.3 and Qwen 2.5 among open-source models.
Even more intriguing, Microsoft introduced a new training paradigm in the technical report—midtraining:
"This innovation enables Phi-4 to handle long-form texts more effectively, maintaining a recall rate of 99% even with a 16K context length."