


Mistral Releases New AI Model "Les Ministraux," Optimized for Laptops and Smartphones
Mistral.AI releases Ministraux, a powerful small-parameter AI model optimized for mobile devices, outperforming Meta and Google models in efficiency.


French AI giant Mistral.AI has open-sourced its latest small-parameter model, Ministraux.
Ministraux is available in two versions, Ministral 3B and 8B, designed specifically for mobile devices such as phones, tablets, and laptops. It excels in text generation, reasoning, function calls, and efficiency, significantly outperforming Meta's Llama-3.2 and Google's Gemma-2. It redefines performance for models under 10 billion parameters.
Mistral.AI was direct in its launch, calling it the "best small open-source model in the world."
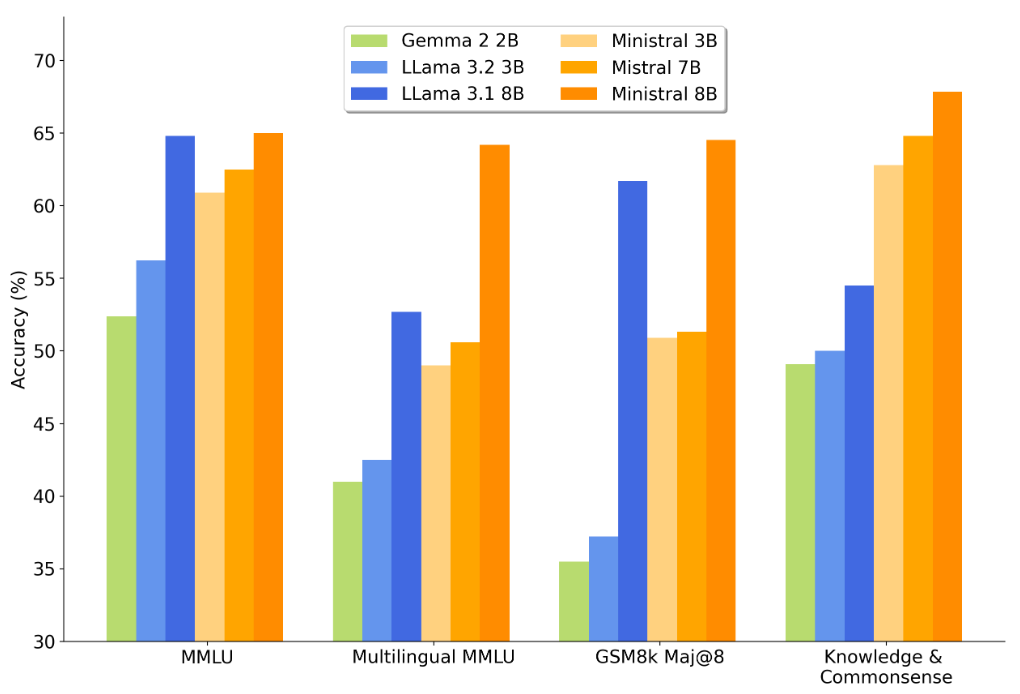
According to Mistral.AI's test results, Ministraux performs impressively. For instance, the 3B model achieved high scores of 60.9, 42.1, 72.7, 64.2, and 56.7 on popular benchmarks such as MMLU, AGIEval, Winogrande, Arc-c, and TriviaQA, respectively.
It outperforms Google’s Gemma-2-2B and Meta’s Llama-3.2-3B by a wide margin, even surpassing models with 7 billion parameters.
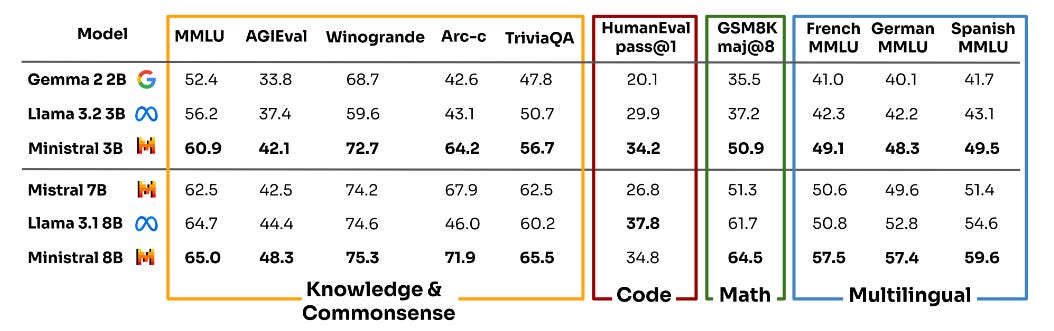
Similarly, the 8B version significantly outshines comparable models from Meta and Google across mainstream benchmarks.
Both Ministral 3B and 8B support a 128k context length, enabling them to handle long text sequences, making them ideal for developing AI translators, offline assistants, and local data analysis tools.
If you're developing a more complex AI assistant, you can combine Ministraux with larger models like Mistral Large to act as intelligent agents handling input parsing, task routing, and low-latency API calls across multiple contexts.
Ministral 8B incorporates an interleaved sliding window attention mechanism, enhancing inference efficiency, memory utilization, and user response times, making it one of the few large models usable offline on mobile devices.
Traditional Transformer self-attention mechanisms calculate similarities between every position in the sequence, leading to quadratic growth in computational demands and memory requirements.
The sliding window attention mechanism restricts the attention range, computing similarities only within a fixed-size window, significantly reducing computational load while maintaining local dependencies.
In terms of pricing, if not deploying locally, you can use Mistral.AI's services, with API pricing at $0.10 per million input/output tokens for Ministral 8B, and $0.04 per million tokens for Ministral 3B.