


O3 Is Not a Magic Trick: Google's Monkey Paper Explores the Key Mechanisms Behind It
Explore Google's August research on scaling inference through repeated sampling, boosting performance by up to 40%. Learn how smaller models outperform larger ones, reducing costs.

The Inference Scaling Driven by O1/O3, Which Google Explored as Early as August This Year.

In August, teams from Stanford, Oxford, and Google DeepMind explored how to scale inference computation by leveraging repeated sampling — achieving up to a 40% performance improvement on coding tasks.
They discovered that smaller models, by generating multiple answers or samples, could perform better on some tasks than larger models making a single attempt. For instance, DeepSeek-Coder, when using five repeated samples, outperformed GPT-4o while costing only one-third of the latter.
What Does This Paper Discuss?
The paper, titled Monkey, draws inspiration from the Infinite Monkey Theorem. According to the theorem, if a monkey randomly presses keys on a typewriter for an infinite amount of time, it will almost certainly type any given text.
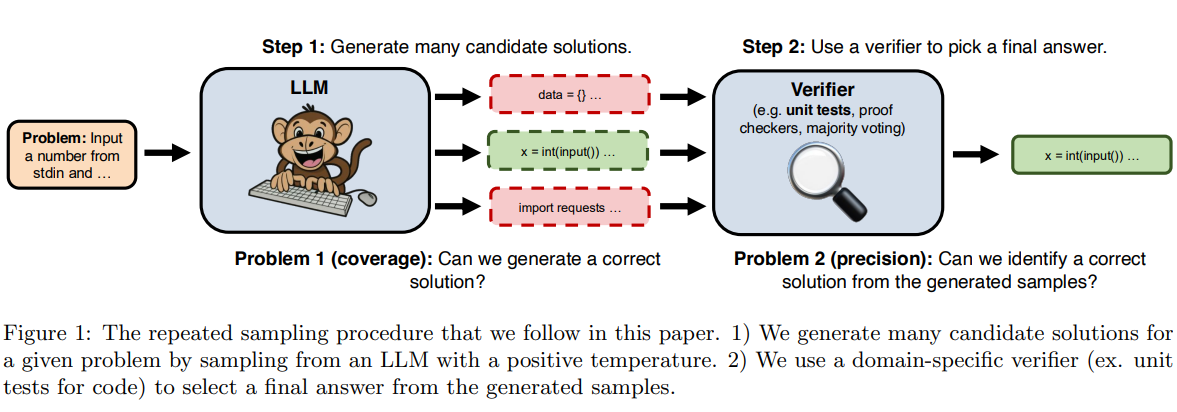
In the context of large models, as long as enough samples are drawn, a large model will eventually find the correct solution. The method described in this paper involves repeated sampling: first, the model generates multiple candidate solutions to a given problem, then a domain-specific validator (such as code unit tests) selects the final answer from the generated samples.