


RAG 2.0 Architecture Implementation: Open-Source Project Surpasses 10K Stars
RAG 2.0: The Next Step in AI Search Evolution You Can't Miss!


Search technology is one of the most challenging technical problems in computer science, and only a few commercial products have managed to solve it effectively.
Most products do not require advanced search capabilities because it does not directly impact user experience.
However, with the explosive growth of LLMs (Large Language Models), every company using LLMs needs a powerful retrieval system. This is where RAG (Retrieval-Augmented Generation) comes in. RAG helps LLMs generate answers by retrieving the most relevant information from internal sources based on user queries.
Imagine an LLM answering user questions. Without RAG, the LLM relies solely on its training knowledge. With RAG, it can search internal documents for relevant information, making it much easier to provide accurate answers, similar to an open-book exam.
As LLMs evolve, new models have longer context windows, allowing them to handle larger inputs. But even if an entire textbook could fit into the context window, search is still essential for several reasons:
1. Enterprises often have multiple versions of similar documents, leading to conflicting information if all are provided to the LLM.
2. Internal scenarios require access control for content loaded into the context window.
3. LLMs can be distracted by content related to the question but irrelevant to the answer.
4. It's inefficient and costly to process millions of unrelated tokens.
RAG quickly became popular due to the rapid integration of various LLMOps tools, streamlining the components needed for the system to function effectively.

The semantic similarity-based approach has been in use for many years:
1. Data Chunking: First, data is divided into chunks (e.g., by paragraphs), then each chunk is converted into vectors using an embedding model and stored in a vector database.
2. Retrieval Process: During retrieval, the query is also converted into a vector, which is then used to find the most similar data chunks in the vector database. These chunks theoretically contain the data most semantically similar to the query.
In this pipeline, LLMOps tools can perform several tasks:
1. Document Parsing and Chunking: Usually, fixed sizes are used to split the parsed text into data chunks.
2. Task Orchestration: Includes sending data chunks to the embedding model (both private and SaaS APIs), storing the resulting vectors along with the data chunks in the vector database, and stitching together the content returned by the vector database according to prompt templates.
3. Business Logic Assembly: For example, generating and returning user dialogue content, connecting dialogue with business systems (like customer service systems), etc.
Although this workflow is straightforward to set up, the search effectiveness is often mediocre due to several limitations of this basic semantic similarity-based system:
1. Embedding Limitations: Embedding processes the entire text chunk, making it unable to highlight specific entities/relationships/events that need higher weights, leading to limited effective information density and overall low recall accuracy.
2. Precision Issues: Embedding cannot achieve precise retrieval. For instance, if a user asks, "What combinations are included in our company's financial plan for March 2024?", the results might include data from other periods or other types of data like operational or marketing plans.
3. Sensitivity to Embedding Models: Embedding models trained for general domains may perform poorly in vertical scenarios.
4. Chunking Sensitivity: Different methods of parsing, chunking, and transforming input data can lead to vastly different search results. The LLMOps tool ecosystem often employs simplistic chunking logic, overlooking the semantics and organization of the data.
5. Lack of Intent Recognition: User queries may lack clear intent. Even if the recall accuracy issue is addressed, finding answers based solely on similarity is not feasible without clear intent.
6. Complex Query Handling: This system struggles with complex queries that require multi-hop reasoning (gathering information from multiple sources and performing multiple steps of reasoning to derive a comprehensive answer).
Thus, this type of RAG system, centered around LLMOps, can be considered version 1.0. Its main characteristics are heavy on orchestration and ecosystem but light on effectiveness and core functionality.
As a result, these tools have quickly become popular, allowing ordinary developers to rapidly build prototype systems. However, they often fall short in meeting the demands of deeper enterprise scenarios, leaving developers stuck.
With LLMs rapidly permeating more scenarios, RAG also needs to evolve quickly. After all, the core of a search system is to find answers, not just the most similar results. Based on this, we envision the future RAG 2.0 working as follows:
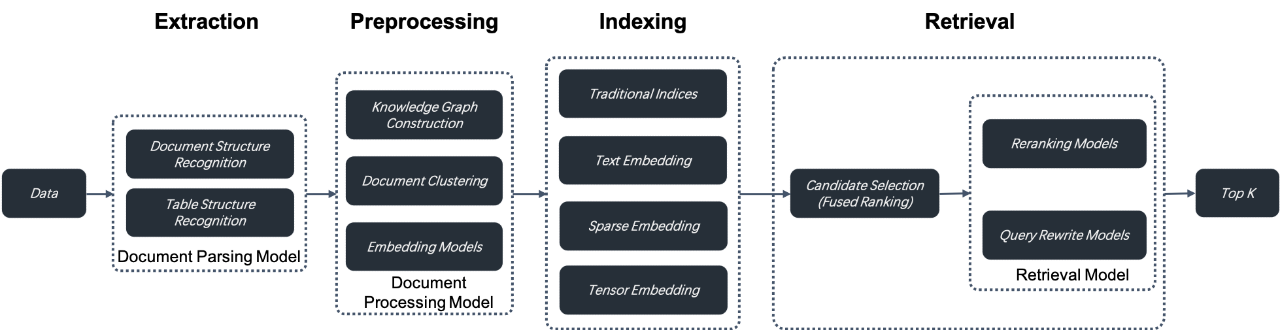
1. RAG 2.0 is a Search-Centric End-to-End System: It divides the entire RAG process into stages such as data extraction, document preprocessing, indexing, and retrieval. Unlike modern data stacks, it can't be orchestrated using LLMOps tools due to the interdependencies and lack of unified APIs and data formats. For example, query rewriting, essential for multi-hop Q&A and intent recognition, involves repeated retrieval and rewriting, where orchestration can interfere with search optimization.
2. Comprehensive and Powerful Database: To address RAG 1.0's low recall accuracy, a database must support multiple retrieval methods like vector search, keyword full-text search, and sparse vector search, and even tensor search for late interaction mechanisms like ColBERT.
a. Keyword Full-Text Search: Essential for precise queries, it helps understand why documents were retrieved, improving explainability. It should handle massive data and support Top K Union semantic searches. Most databases offering BM25 and full-text search lack enterprise-grade capabilities.
b. Mixed Retrieval Methods: Studies show combining keyword search, sparse vectors, and vector search achieves SOTA results, necessitating built-in support for such methods in databases.
c. Tensor Search: A new retrieval method using models like ColBERT. It provides more accurate search results by capturing complex interactions between queries and documents. Though slower than vector search, it's faster than Cross Encoder models and retains high recall accuracy.
d. OpenAI's Acquisition of Rockset: Rockset's index capabilities and cloud-native architecture made it an attractive choice for OpenAI, emphasizing its strength in combining keyword and vector searches.
3. Optimizing the Entire RAG Pipeline: Beyond databases, each RAG stage needs optimization:
a. Data Extraction and Cleaning: Data must be segmented and iteratively refined based on search results. This involves handling various document formats and is more complex than SQL-based ETL processes.
b. Data Preprocessing: Before indexing, data may need knowledge graph construction, document clustering, and embedding model fine-tuning to improve retrieval accuracy.
c. Retrieval Process: This includes initial filtering and detailed re-ranking, often outside the database, and involves continuous query rewriting based on identified user intent until satisfactory answers are found.
Each of these stages works in concert with the database to ensure effective Q&A.
Thus, RAG 2.0 is more complex than RAG 1.0, relying on databases and various models, necessitating a platform for ongoing iteration and optimization. This need led to the development of open-source RAGFlow.
RAGFlow doesn't use existing RAG 1.0 components but redefines the entire pipeline to address LLM search system challenges fundamentally.
Currently, RAGFlow is in its early stages, with each component evolving. Its correct approach to problem-solving has earned it significant GitHub recognition in a short time. But this is just the beginning.
Start with the open-source project here: https://github.com/infiniflow/ragflow