RAG is Dead, Gemini Must Ascend
Best Practices for Gemini


Simplistic RAG systems may be on the verge of obsolescence, yet more personalized versions will persist.
I’ve recently delved into Gemini 1.5 Pro, and as an entrepreneur in the AI domain, I have some insights to share with you.
RAG is a search technology that retrieves desired content by comparing the similarity of information.
Considering RAG’s primary application in information retrieval, I’ve found that LLMs excel notably in this regard.
Currently, datasets in the market typically do not exceed a token count of one million.
Similar to OpenAI’s Assistant API, if the Gemini API could handle large files, then cost becomes crucial.
In terms of cost, processing one million tokens with Gemini Pro 1.0 is priced at $0.125, while the cost for the 1.5 Pro version will be significantly reduced.
This means we can accomplish more tasks at a lower cost.
Moreover, the retrieval capability of LLMs is extremely potent, unaffected by data formats, adeptly handling code, text, audio, or video alike.
More impressively, Gemini can even swiftly identify keyframes in videos.
This is a feature many RAG systems have yet to achieve.
However, retrieving information is just the beginning; understanding and reasoning are the crucial elements.
LLMs are continuously improving in this aspect.
What then is the future of RAG, and what changes will Gemini 1.5 Pro introduce? These questions merit our further attention.
Why Do We Need RAG?
When applying large language models (LLMs) in specific domains, we have three main technical approaches at our disposal.
The first is Retrieval-Augmented Generation (RAG), which involves using a retrieval system to find parts of a large corpus of documents relevant to a user’s query and then integrating these documents into the input for the LLM to generate results.
The second approach utilizes the large model’s capacity for processing long texts, inputting all relevant documents en masse for it to generate outcomes independently.
The third approach is fine-tuning, embedding domain knowledge directly into the model’s parameters.
However, fine-tuning models can be prohibitively expensive for the average user, making RAG and long text processing the more commonly chosen methods.
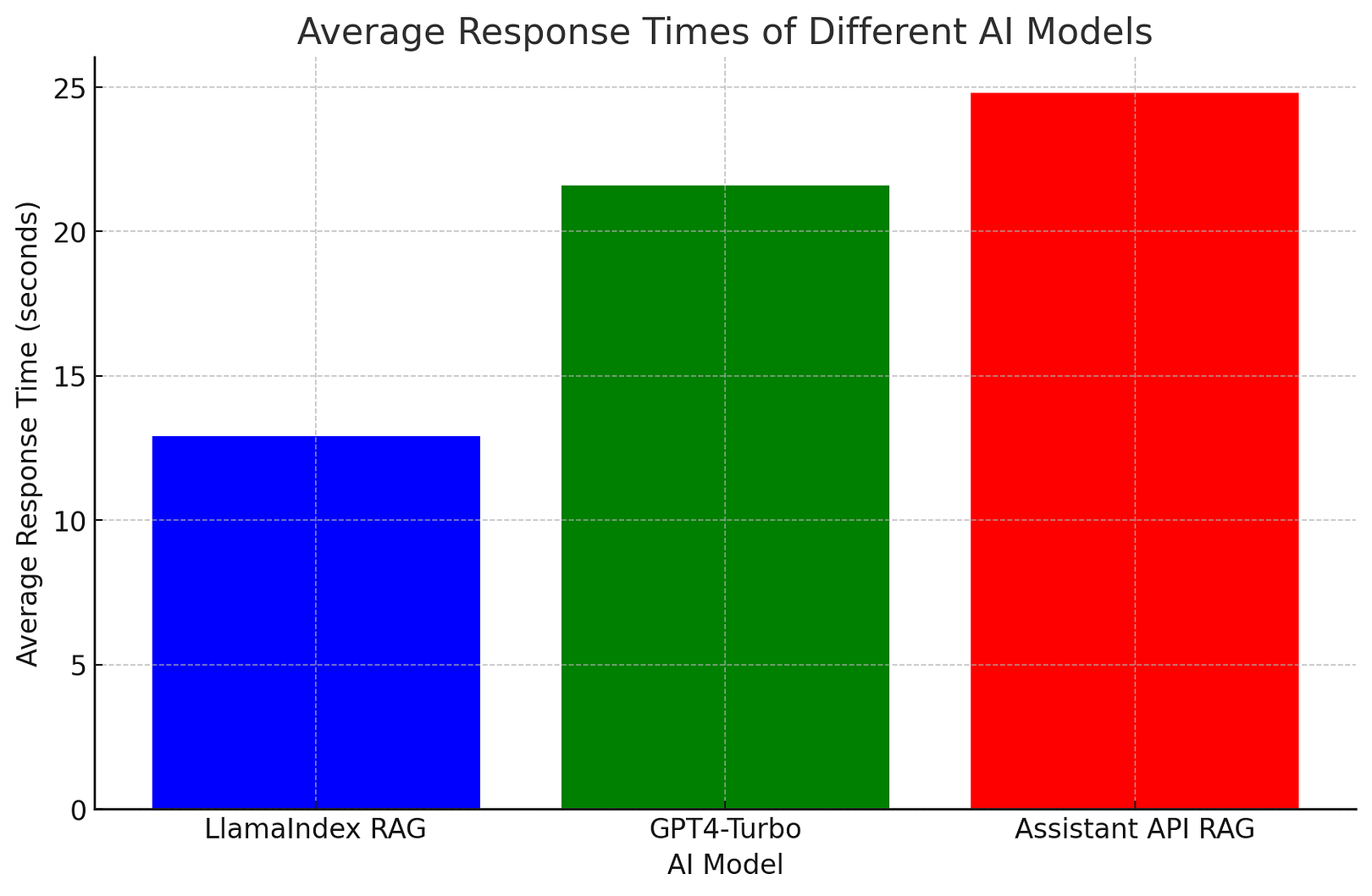
Atai Barkai conducted a comparative study on RAG.
He observed that the average response time for RAG solutions was the shortest at 12.9 seconds; GPT-4’s response times varied more significantly, ranging between 7 to 36 seconds; while the Assistant API’s RAG solution had the longest response time, averaging at 24.8 seconds.