


Stanford’s Llama3-V Plagiarism Admitted, Ignoring Chinese Models’ Consequences
This Is the Consequence of Ignoring Chinese AI Innovations


Last October, Vinod Khosla, a big VC in Silicon Valley, posted on X. He was worried that China was copying America's open-source large AI models.
Eight months later, this worry came back. Recently, people in the AI community were talking about plagiarism claims against a Stanford AI team.
The Stanford team published a paper about "Llama 3-V." They said they trained this model for only $500. They claimed it was better than GPT-4v, Gemini Ultra, and Claude Opus. And it was 100 times smaller than GPT-4v.
Because it came from a top university, was cheap, and performed well, Llama 3-V became very popular quickly.
However, some people noticed that Llama 3-V's structure, files, and code were almost the same as MiniCPM-Llama3-V 2.5. This is a model made by Tsinghua University and OpenBMB.
More and more evidence of plagiarism between Llama 3-V and MiniCPM-Llama3-V 2.5 was shared online.
Internal Team Conflict
As more people talked about the problem, on June 3, two authors named Aksh Garg and Siddharth Sharma finally responded publicly on X.
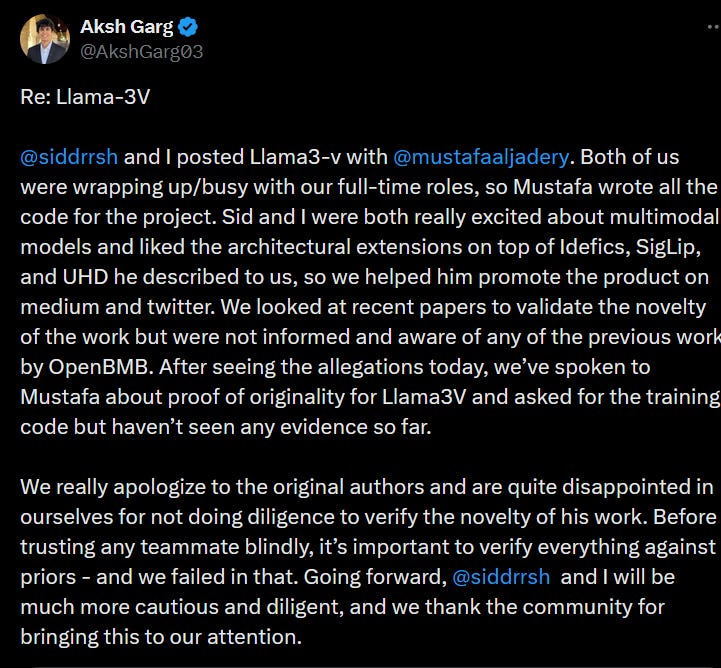
First, they said sorry to the original makers of MiniCPM. They said they hoped their co-author Mustafa Aljadery would respond first, but he had been unreachable since the day before.
While all three of them released Llama3-V, Mustafa was the only one who did the coding. Aksh and Siddharth said, "Sid and I were very interested in the multimodal model and liked the architecture based on Idefics, SigLip, and UHD that Mustafa described. So our role was to help promote the model online. We reviewed recent papers to check if the work was new, but we did not know about any earlier work by OpenBMB."
They expressed disappointment in themselves for not conducting proper due diligence to verify originality. "We should have compared our work with previous research, and we failed to do so. We take full responsibility for this oversight. In the future, @siddrrsh and I will be more careful and diligent. We sincerely thank the community for pointing this out. We have respected the original work and removed all references to Llama-3V. We apologize again."
The response was also updated in the project article on Medium:
"Many thanks to those who pointed out the similarities to previous research in the comments. We recognize that our architecture closely resembles OpenBMB's 'MiniCPM-Llama3-V 2.5: A GPT-4V Level Multimodal LLM on a Phone,' which they implemented earlier than us. To respect the original authors, we have taken down our original model.
The link to the original authors' code repository can be found here: https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file
Mustafa Aljadery, identified as the main person responsible for the plagiarism, has not yet responded, and his X account is now private.

However, the apology and self-defense from the two team members did not have a positive effect and instead led to further criticism.
Netizens pointed out sharply, "Blaming everything on one person is wrong. If you didn’t do the work, you shouldn't take the credit. But you did, so you must share the responsibility. You could have helped promote it without claiming co-authorship."
"So your plan was to share credit for a project you didn't participate in at all. Makes sense."
"Clearly, blaming one person for the actions of all three is not wise."
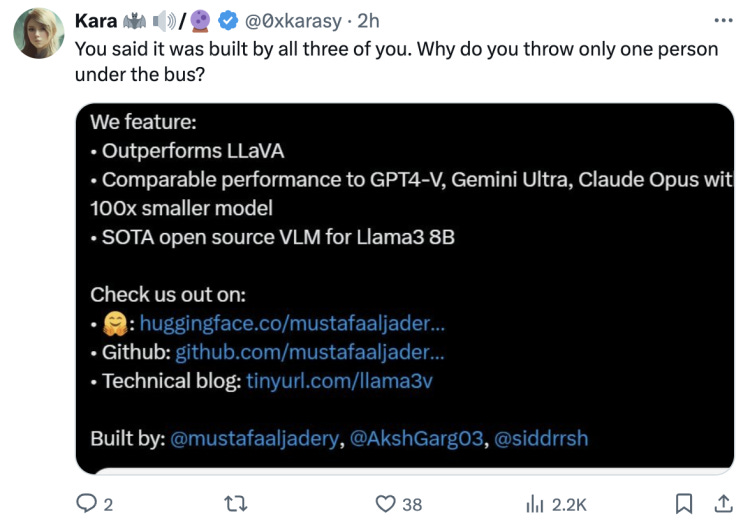
When the project was published, it was clearly labeled as a joint effort. Now, in the face of backlash, the attempt to distance themselves from responsibility has earned widespread disdain.
Overview and Evidence of Plagiarism
To understand this incident, we need to revisit the original announcement by the Stanford team on May 29. In it, they described the creation of Llama 3-V:
"Llama3 emerged, outperforming GPT 3.5 in almost all benchmarks and surpassing GPT4 in several aspects. Then GPT 4o reclaimed the throne with its sophisticated multimodal capabilities. Today, we present a game-changing product: Llama3-V."
Aksh and Siddharth did not mention MiniCPM-Llama3-V 2.5 in their response. However, some careful users on HuggingFace still saw copying.
Llama3-V then gave a different explanation. They said they only used the tokenizer from MiniCPM-Llama3-V 2.5. They claimed they started their work before MiniCPM was released. But this did not seem likely.
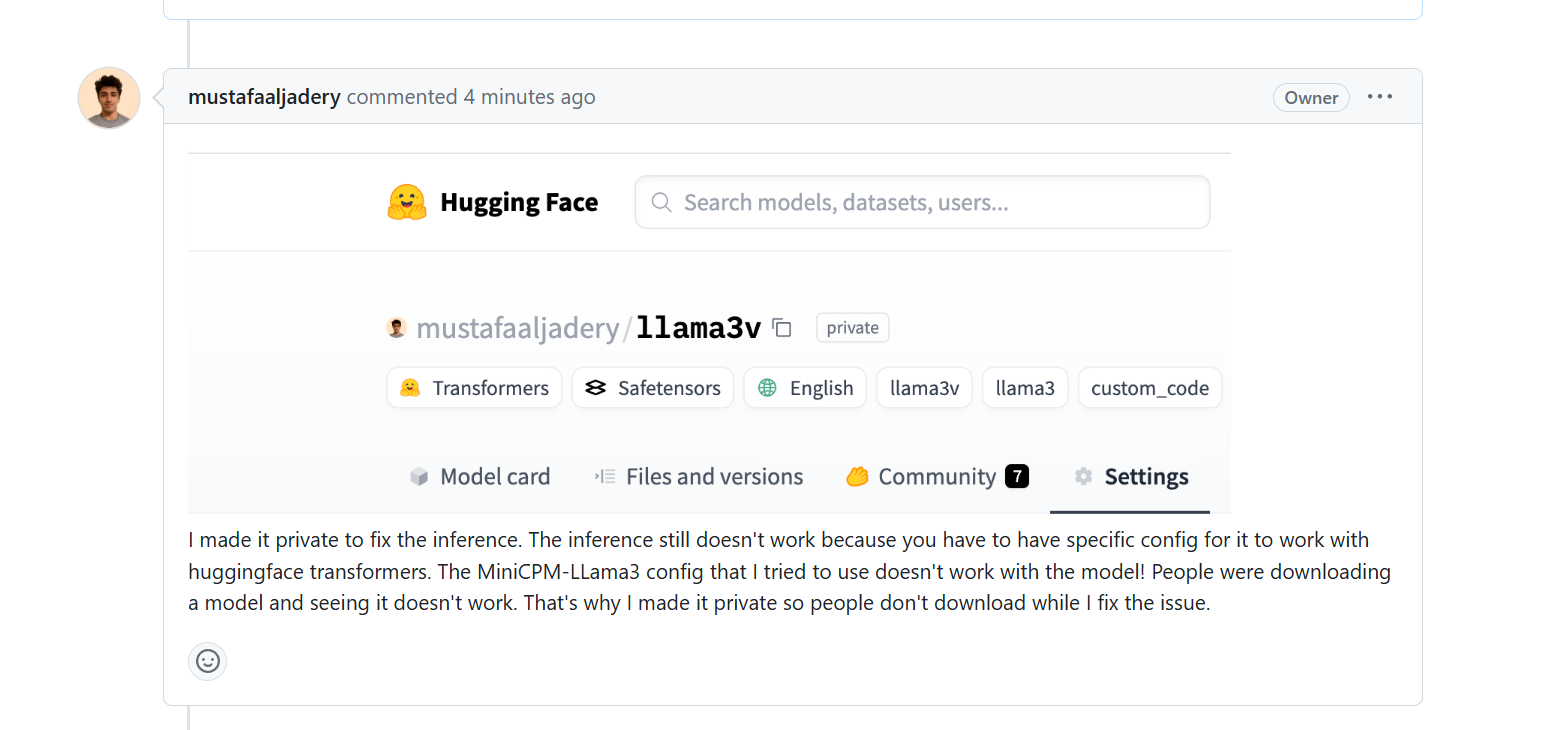
Netizens continued to investigate, posting evidence on GitHub Issue and X starting June 2.
Evidence 1: Identical Model Structure and Code
Llama3-V's code was very similar to MiniCPM-Llama3-V 2.5. The code had small changes like renaming variables. The code was almost the same.
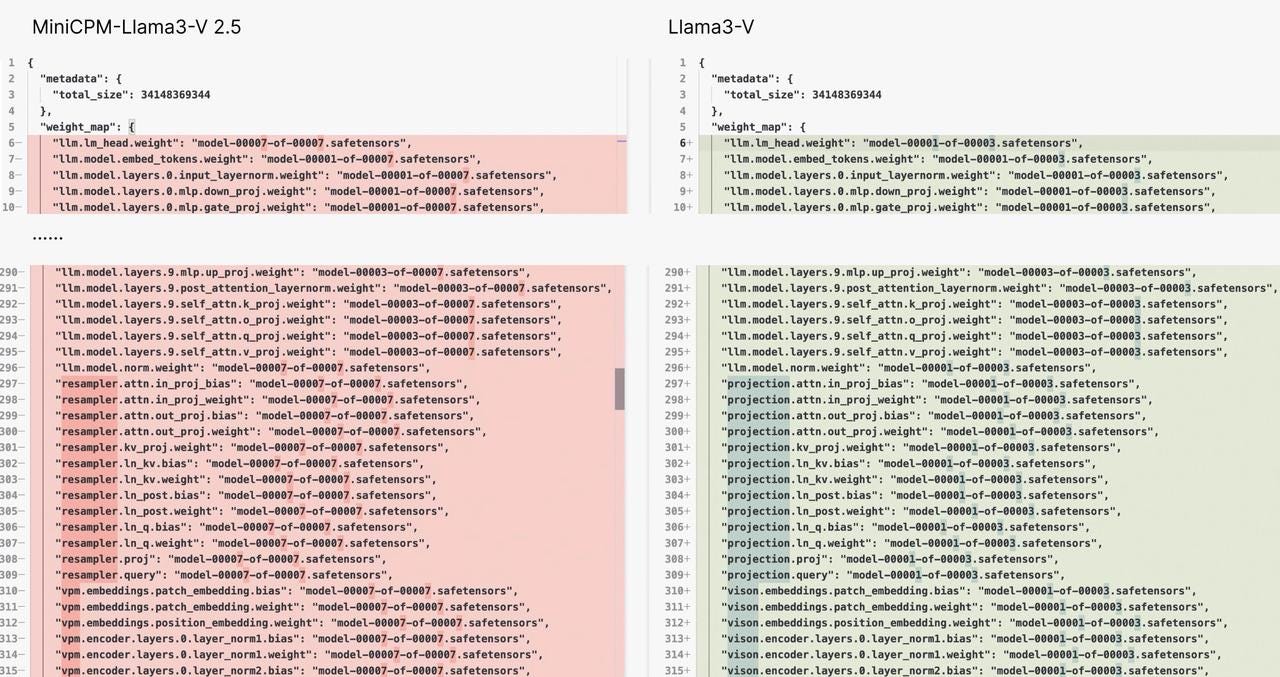

The authors said they used LLaVA-UHD architecture. However, they did not say that Llama3-V's code was almost the same as MiniCPM-Llama3-V 2.5. Llama3-V's code was very different from LLaVA-UHD. They used the same tokenizer as MiniCPM-Llama3-V 2.5, including special symbols.
Evidence 2: Technical Blog Errors
The blog and code of Llama3-V showed they did not fully grasp their own work. For example, they described the Perceiver resampler as using cross-attention instead of self-attention with two layers.
Even worse, the blog wrongly said Sigmoid activation was needed for visual features. But the code was right.

Evidence 3: Llama3-V = MiniCPM-Llama3-V 2.5 + Gaussian Noise
Netizens reported that the code provided by Llama3-V didn't work with HuggingFace's checkpoint. However, renaming variables in Llama3-V to those used in MiniCPM-Llama3-V 2.5 made it function with MiniCPM-V.
Moreover, adding simple Gaussian noise to MiniCPM-Llama3-V 2.5's checkpoint produced a model that behaved very similarly to Llama3-V, suggesting that Llama3-V was essentially a noisy version of MiniCPM.

Evidence 4: Recognizing Ancient Chinese Text
Another strong proof was that MiniCPM-Llama3-V 2.5 could recognize ancient Chinese text from the Warring States period written on bamboo slips. The training data for this was only available to Tsinghua's language lab and OpenBMB, not the public.

Surprisingly, Llama3-V could also recognize these bamboo slip texts, even though they did not have access to this private data. This would be impossible without copying. OpenBMB tested various Llama3-based visual-language models on 1,000 bamboo slip images. They found that Llama3-V and MiniCPM-Llama3-V 2.5 had an 87% overlap, while other models had a 0% overlap.

Additionally, Llama3-V showed similar abilities to read Chinese text, which is unlikely with just a $500 budget.
More and more people got angry about this online, on X, HuggingFace, Reddit, Weibo, and Zhihu. They criticized Llama3-V, forcing them to remove all project links from the community.
The CEO of OpenBMB, Li Dahai, said he felt very bad, "Technological innovation is hard work. Every project is the result of our team's efforts. We hope our work is recognized for the right reasons, not like this."
Llama3-V's failure to respect and credit previous open-source work severely damaged the principles of open-source sharing.
X users were less forgiving, saying, "It's hard to trust anything now. Everything can be faked and plagiarized, from GitHub releases to resumes."
Examination of the Authors
This controversy involves three young authors with impressive backgrounds:
Siddharth Sharma studies computer science at Stanford University. He focuses on machine learning and has experience working with technology companies. An influential person in AI follows him on Twitter.
Siddharth has a lot of experience developing large AI models. He has written articles about open-source AI, data systems, quantum computing, and computer vision.
Aksh Garg published the article on Medium. He is also a Stanford computer science student with a high GPA. He has interned as an engineer at companies like SpaceX and as a researcher in machine learning.
Mustafa Aljadery is a software engineer working full-time at Beehiiv. He has degrees from USC in deep learning and mathematics. He has interned at finance and technology companies and conducted AI research.
The three authors have strong technical backgrounds in AI, which made their plagiarism more surprising. They copied work and claimed it as their own, violating open-source principles.
Some people said the plagiarism happened because Chinese AI models are not well-known, even though they are good. A DeepMind engineer noted the strong but ignored MiniCPM model did not get much attention compared to the copied Llama3-V.
The founder of an AI community said China's machine learning work is impressive in areas like language models and diffusion models. But this work is often overlooked.
Yann LeCun, Meta's chief AI scientist and known as the "Godfather of AI," stated: "AI is not a weapon. Whether we open-source our technology or not, China will not lag behind. They will control their own AI and develop their native tech stack."
I am writing an ebook on “Gaining Followers Quickly on Medium” because I am the best proof — I’ve gained over 5,000 followers in just one month. Stay tuned!


