


Today's Open Source (2024-07-12): InternVL 2.0 Multimodal Model Series
Discover the latest in AI: InternVL-2.0, EchoMimic, LAMDA-TALENT, ServerlessLLM, and FlashAttention-3. Boost your projects with these powerful tools!

I'd like to share some interesting AI open-source models and frameworks from today.
Project: InternVL-2.0
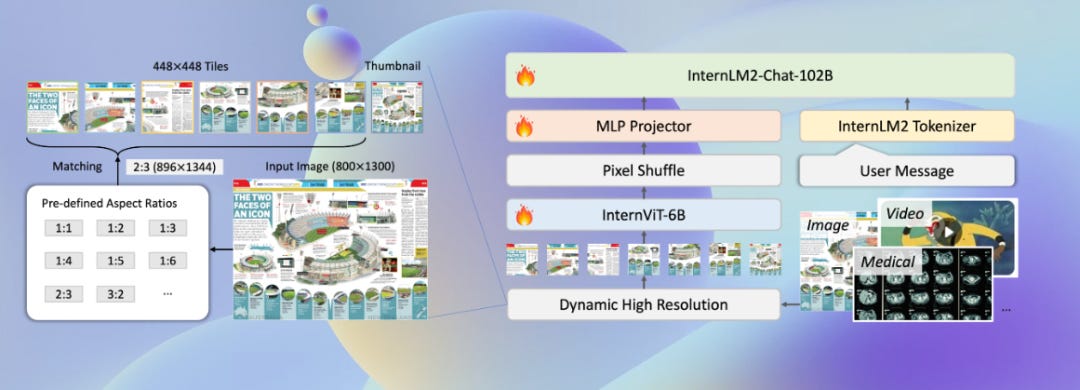
InternVL 2.0, developed by Shanghai AI Laboratory, is part of the "Shusheng·Wanxiang" multimodal large model series. It includes various instruction-tuned models with parameters ranging from 1B to 108B. The largest model (pro version) requires an API trial request. InternVL 2.0 is trained with an 8k context window and includes long text, multiple images, and video data. Compared to InternVL 1.5, it has significantly improved capabilities in handling these input types.
Project: EchoMimic

EchoMimic, released by Ant Group, is an open-source project that generates realistic audio-driven portrait animations with editable keypoint control. It can create synchronized facial expressions and lip movements based on input audio and supports pose driving and audio-keypoint hybrid driving.
Project: LAMDA-TALENT

LAMDA-TALENT is a comprehensive toolbox and benchmark platform for table data learning. It integrates over 20 advanced deep learning models, 10 classic algorithms, and 300 diverse datasets to enhance table data model performance. It includes various classic methods, tree-based methods, and popular deep learning methods, making it easy to add new datasets and methods.
Project: ServerlessLLM

ServerlessLLM aims to make LLMs serverless, offering cost-effective and scalable deployment solutions. This project removes the need for users to manage servers and infrastructure, making LLM deployment more convenient. The serverless approach allows automatic scaling based on demand, ensuring smooth operation under varying traffic levels without manual intervention. ServerlessLLM provides an easy-to-use interface for deploying and managing large language models.
Project: FlashAttention-3
FlashAttention-3 has released its beta version, which is 1.5 to 2.0 times faster than FlashAttention-2, reaching up to 740 TFLOPS. This achieves 75% of the theoretical maximum FLOPS utilization of the H100 GPU, up from 35% previously. FlashAttention-3 uses reordered algorithms and tiling and recomputation techniques to reduce memory usage from quadratic to linear, significantly lowering memory consumption.

