


Today's Open Source (2024-07-15): AuraFlow, 6.8B Stream-based Open-Source Text-to-Image Model
Open-source AI models disrupting vision, language, and search: AuraFlow text-to-image generation, MambaVision hybrid vision backbone, PDF-Extract-Kit toolkit, STORM knowledge curation, BM25S fast lexi

Here are some interesting AI open-source models and frameworks I discovered today.
Project: AuraFlow

AuraFlow v0.1 is a fully open-source stream-based text-to-image generation model developed by the Fal team. It excels in prompt adherence.
AuraFlow improves MMDIT by replacing most MMDIT layers with a single large DiT block, enhancing computational efficiency. The optimal model structure with a width-to-length ratio of 20-100 was found, resulting in a model with 6.8B parameters.
This model achieved state-of-the-art results on GenEval and is in the testing phase. It is currently supported by ComfyUI and Diffusers.
https://huggingface.co/fal/AuraFlow
Project: MambaVision
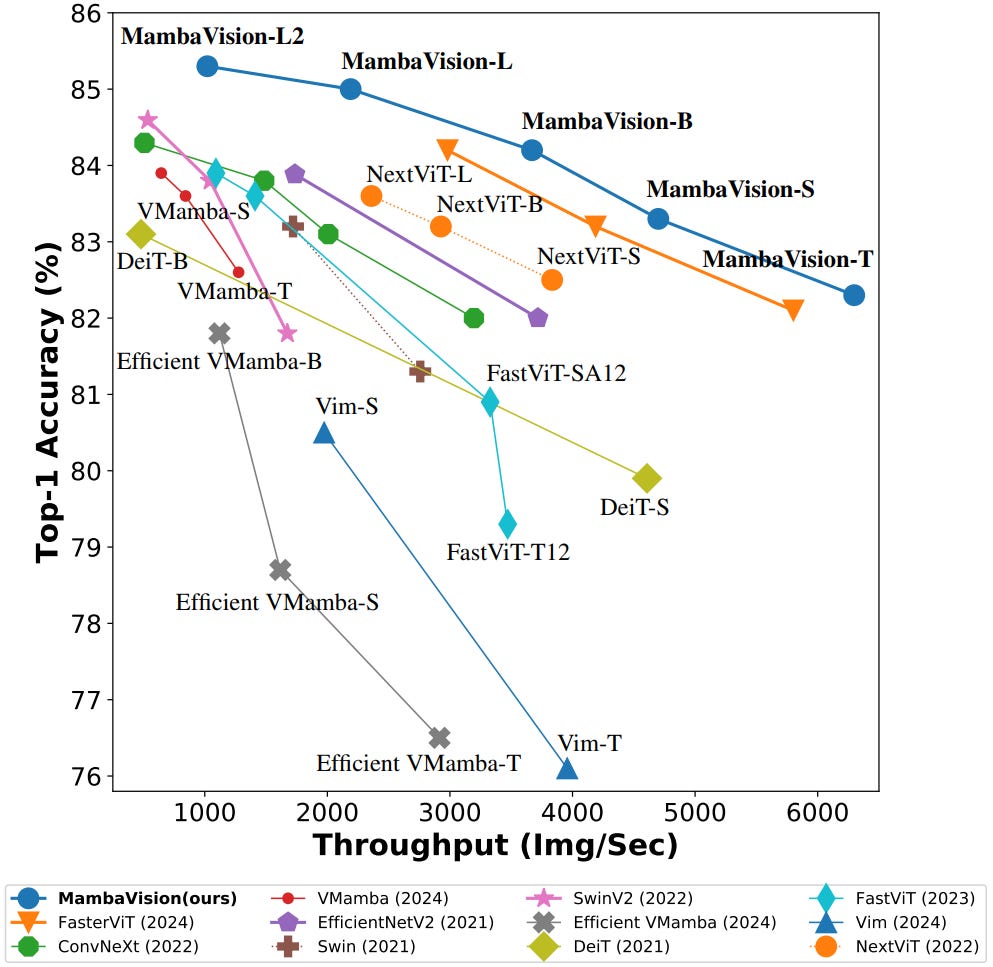
MambaVision is a hybrid Mamba-Transformer vision backbone network implemented in PyTorch.
It enhances global context modeling with hybrid blocks in a symmetrical path, achieving new SOTA Pareto frontier performance in Top-1 accuracy and throughput.
MambaVision features a hierarchical architecture combining self-attention and hybrid blocks, supports any image resolution, and offers various pre-trained models.
https://arxiv.org/abs/2407.08083
https://github.com/nvlabs/mambavision
Project: PDF-Extract-Kit
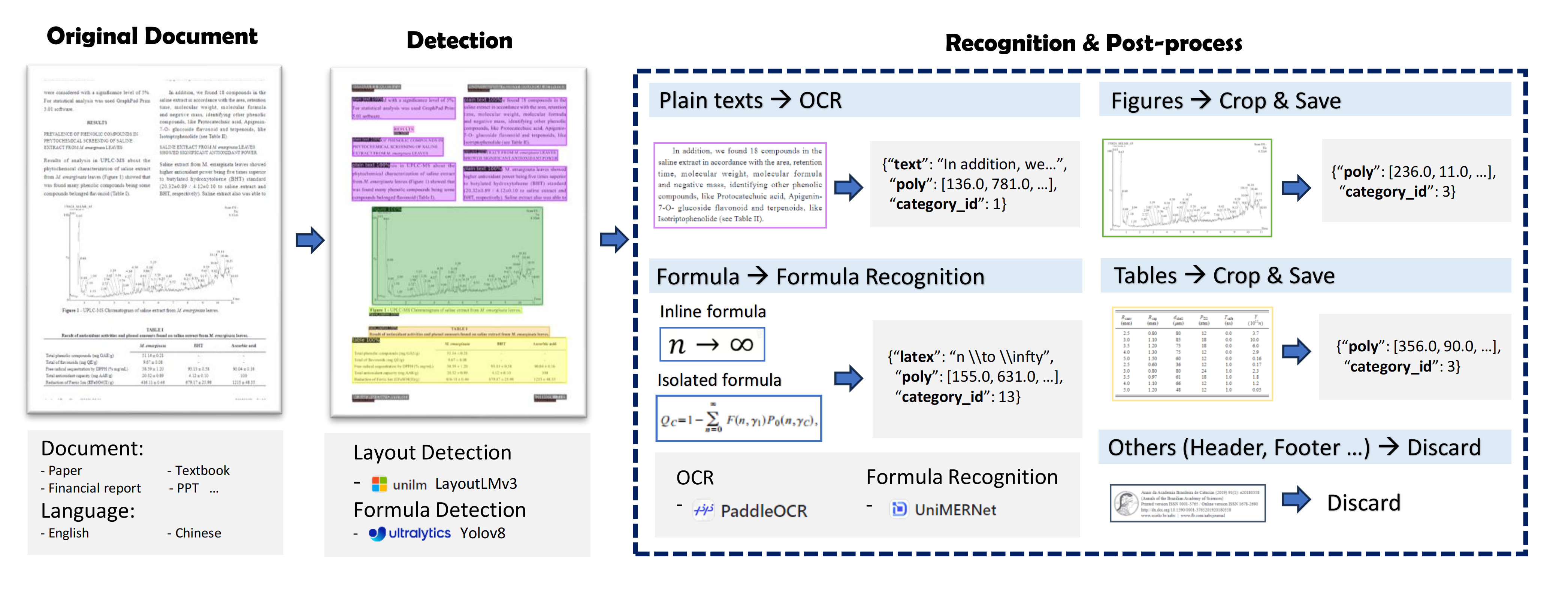
PDF-Extract-Kit is a high-quality toolkit for extracting content from PDFs.
It breaks down PDF content extraction into multiple components, including layout detection, formula detection, formula recognition, and optical character recognition.
Using LayoutLMv3 for area detection, YOLOv8 for formula detection, UniMERNet for formula recognition, and PaddleOCR for text recognition, PDF-Extract-Kit achieves precise detection in various document types.
https://github.com/opendatalab/PDF-Extract-Kit
Project: STORM

STORM, developed by Stanford University, is an LLM-driven knowledge integration system for writing Wikipedia-like articles from scratch.
It can research specific topics and generate complete reports with citations. STORM's core functions are divided into two stages: prewriting and writing.
In the prewriting stage, the system gathers references and creates an outline through internet research. In the writing stage, it uses the outline and references to generate the full article with citations.
STORM can handle single topics or batch datasets and offers automated evaluation for both outline and article quality.
https://arxiv.org/abs/2402.14207
https://github.com/stanford-oval/storm
Project: BM25S

BM25S is a super-fast BM25 library implemented in pure Python, utilizing Scipy sparse matrices for storing precomputed document scores.
It aims to improve query scoring speed, offering performance improvements in single-threaded environments compared to popular libraries like Elasticsearch.
BM25 is a widely used text retrieval ranking function and a core component of search services.
https://arxiv.org/abs/2407.03618
https://github.com/xhluca/bm25s
Project: Phi3V-Finetuning
Phi3V-Finetuning is a parameter-efficient finetuning script for Microsoft's powerful multimodal language model Phi-3-vision.
This project supports training on mixed NLP and vision-language data, offering various configurations and options for flexible finetuning.
