


Today's Open Source (2024-08-26): ByteDance's Multimodal Model; Kunlun's 1 Billion Drama Dataset
Discover top AI open-source projects like Show-o for multimodal generation, LitServe for fast AI model serving, and SkyScript-100M for massive drama datasets.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: Show-o
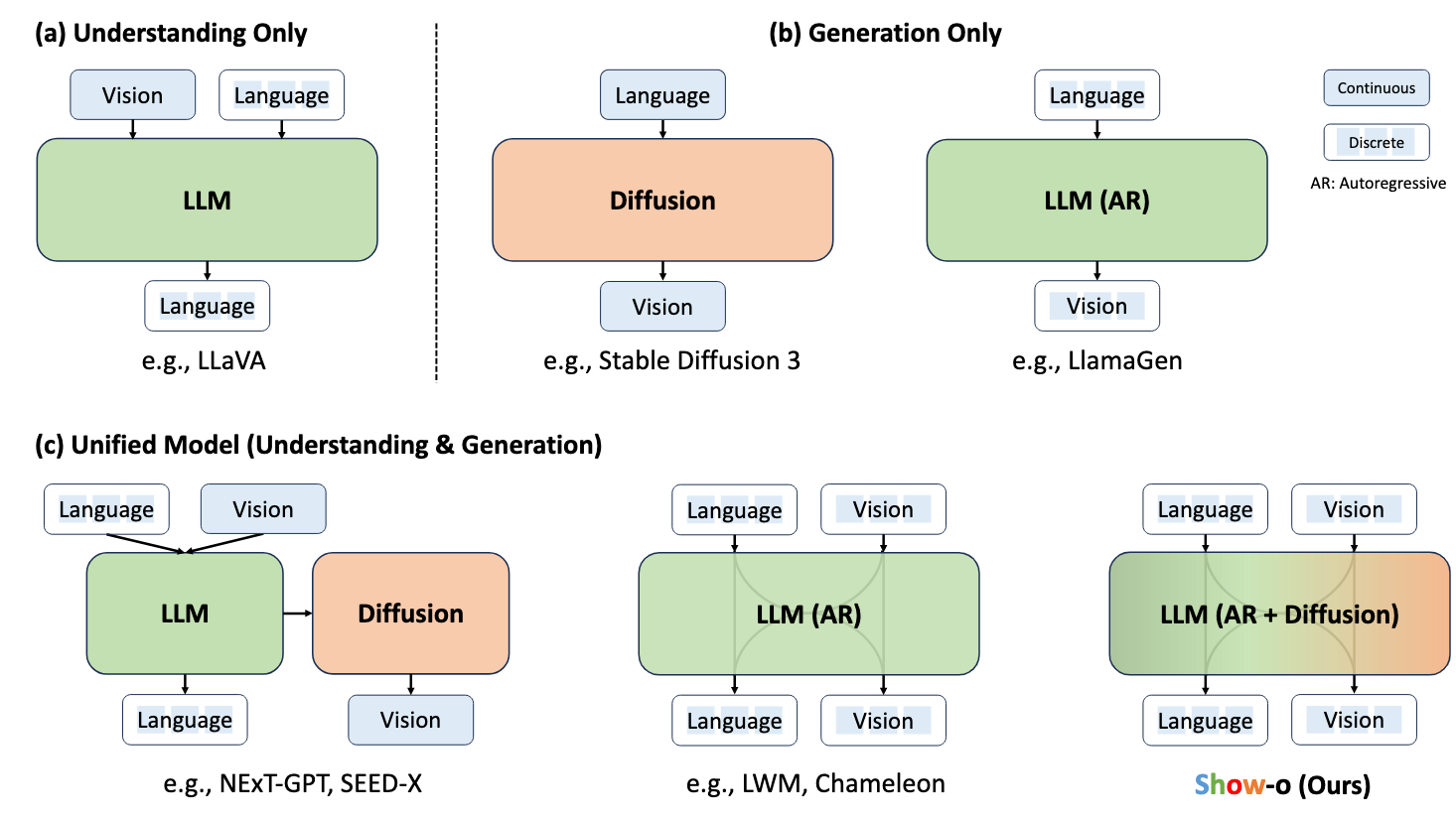
Show-o is a single Transformer model proposed by Show Lab and ByteDance. It unifies multimodal understanding and generation.
The model handles tasks like image captioning, visual question answering, text-to-image generation, text-guided image inpainting, and extrapolation.
Show-o merges autoregressive and (discrete) diffusion modeling to adapt to various mixed-modal inputs and outputs. It shows performance comparable to or better than existing models in benchmarks, highlighting its potential as the next-generation foundational model.
https://github.com/showlab/show-o
https://arxiv.org/abs/2408.12528
Project: LitServe

LitServe is a user-friendly and flexible AI model-serving engine built on FastAPI.
It supports batch processing, streaming, and automatic GPU scaling. No need to rebuild a FastAPI server for each model. LitServe runs at least twice as fast as standard FastAPI.
https://github.com/Lightning-AI/LitServe
Project: Hugging Face Inference Toolkit

The Hugging Face Inference Toolkit is an official toolset for serving Transformers models in containers.
It provides default preprocessing, prediction, and postprocessing functions for Transformers, diffusers, and Sentence Transformers models.
Users can customize it with a handler.py file. This toolkit, integrated with the Hugging Face Hub, is the “default” choice for inference endpoints.
https://github.com/huggingface/huggingface-inference-toolkit
Project: ReHiFace-S

ReHiFace-S, short for "Real Time High-Fidelity Faceswap," is a real-time high-fidelity face-swapping algorithm developed by Guiji AI.
With open-source digital human generation capabilities, developers can easily create large-scale digital humans and enable real-time face-swapping.
https://github.com/GuijiAI/ReHiFace-S
Project: Dataset Viber

Dataset Viber is a toolkit designed to simplify AI model data preparation.
It offers data collection, annotation, and embedding features, supporting various data types like text, chat, and images. The tool can log data in local CSV files or on the Hugging Face Hub and supports running in .ipynb notebooks.
https://github.com/davidberenstein1957/dataset-viber
Project: SkyScript-100M

SkyScript-100M is a dataset containing 1 billion pairs of short script dialogues and shooting scripts.
This project collected 6,660 popular short dramas, totaling about 80,000 episodes and 2,000 hours of content, with a data size of 10 TB.
Through keyframe extraction and annotation, about 10 million shooting scripts were generated, and 100 script reconstructions were conducted based on the self-developed large short drama generation model, SkyReels.
