


Today's Open Source (2024-09-11): Zhipu Releases LongCite to Boost LLM Citation Accuracy
Explore LongCite, MiniMind, SWIFT, and other innovative open-source projects that enhance LLMs, AI workflows, and knowledge graph extraction. Ideal for developers and researchers.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: LongCite

LongCite is a project that enables large language models (LLMs) to generate detailed citations in long-context question-answering tasks.
It offers two open-source models: LongCite-glm4-9b and LongCite-llama3.1-8b. These are based on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context.
Users can generate accurate responses with precise sentence-level citations, making it easier to verify the output.
https://github.com/THUDM/LongCite
Project: MiniMind

MiniMind is an open-source project aimed at quickly training a small GPT model with only 26M parameters from scratch.
It's an improvement based on DeepSeek-V2 and Llama3. It covers all stages, including data processing, pre-training, instruction fine-tuning, and preference optimization.
MiniMind is highly lightweight and suitable for fast inference and training on personal GPUs, lowering the entry barrier to LLMs.
https://huggingface.co/jingyaogong/minimind-v1
Project: SWIFT

SWIFT supports the training, inference, evaluation, and deployment of over 300 LLMs and 50 MLLMs.
Developers can use this framework for research or production, handling tasks from training to application deployment.
It includes lightweight training solutions like PEFT and a full Adapters library for the latest techniques like NEFTune, LoRA+, and LLaMA-PRO.
For users unfamiliar with deep learning, there is a Gradio web UI for training and inference, along with deep learning courses and best practices.
https://github.com/modelscope/ms-swift
Project: iText2KG

iText2KG is a Python package designed to extract entities and relationships from text documents, using large language models to build a consistent knowledge graph step by step.
It works in a zero-shot manner, extracting knowledge across various domains without specific training.
The package includes document distillation, entity extraction, and relationship extraction modules to ensure accurate parsing of unique entities and relationships.
It updates the knowledge graph and integrates new documents into Neo4j for visualization.
https://github.com/AuvaLab/itext2kg
Project: Langflow

Langflow is a low-code application builder designed for RAG and multi-agent AI applications.
Built on Python, it is highly compatible with any model, API, or database.
Users can create and test workflows in a visual IDE with drag-and-drop and iterate instantly in the Playground.
Langflow also supports multi-agent orchestration, conversation management, and retrieval, allowing workflows to be published as APIs or exported as Python applications.
https://github.com/langflow-ai/langflow
Project: MemoRAG
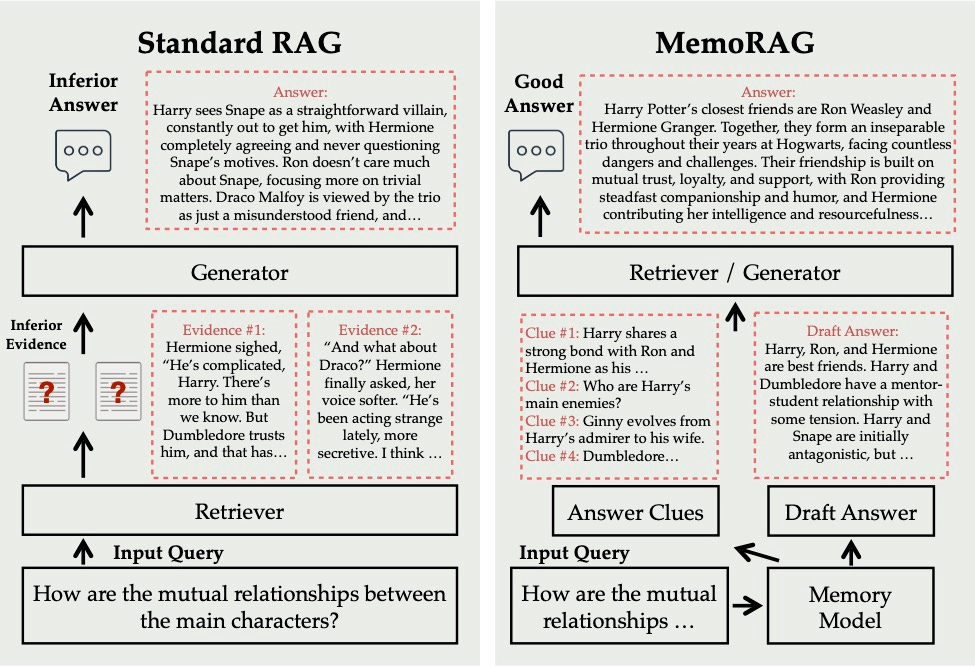
MemoRAG is an innovative RAG framework built on efficient long-memory models.
Unlike standard RAGs, which focus on explicit information retrieval, MemoRAG leverages memory models to gain a global understanding of the entire database.
By recalling query-specific hints from memory, MemoRAG improves evidence retrieval, generating more accurate and context-rich responses.
https://github.com/qhjqhj00/MemoRAG
Project: Agent4SE-Paper-List
This project systematically summarizes the use and progress of LLM-based agents in software engineering (SE).
By enhancing LLMs' ability to access and utilize external resources and tools, LLM agents significantly extend the versatility and expertise of LLMs.
It collects 106 related papers and categorizes them by software engineering tasks and agent architecture, highlighting open challenges and future directions.
