


Today's Open Source (2024-09-27): ProX Automates Pre-training Data Cleaning
Discover top open-source AI projects like ProX for data optimization, Show-Me for LLM visualization, and HelloBench for benchmarking long-text generation.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: ProX

ProX is a data optimization framework based on language models, designed to improve the quality of data used for pre-training large language models.
Unlike relying on human experts to create rules, ProX treats data optimization as a programming task, allowing models to automatically clean and enhance each data sample at scale.
ProX optimizes data through document-level and block-level programming and execution, significantly boosting model performance and domain adaptability.
https://github.com/GAIR-NLP/ProX
Project: Show-Me

Show-Me is an open-source app that provides a visual and transparent alternative to traditional large language model (LLM) interactions.
It breaks complex problems into well-reasoned subtasks, enabling users to understand the LLM’s step-by-step thinking. The app uses LangChain to interact with LLMs and visualizes the reasoning process through dynamic graphics.
https://github.com/marlaman/show-me
Project: LLM-Dojo

LLM-Dojo is an open-source learning hub for large models, offering clean and easy-to-read code for building model training frameworks. It supports popular models like Qwen, Llama, and GLM.
The project also includes RLHF frameworks such as DPO, CPO, KTO, and PPO, making it easy for users to build their own training and reinforcement learning frameworks.
https://github.com/mst272/LLM-Dojo
Project: Curiosity

Curiosity is an experimental project that explores building a user experience similar to Perplexity using the LangGraph and FastHTML tech stack.
At its core is a simple ReAct Agent, enhanced with Tavily's search for better text generation. The project supports multiple large language models (LLMs) and focuses on front-end visuals and interactivity.
https://github.com/jank/curiosity
Project: HelloBench
HelloBench is an open-source benchmarking tool for evaluating the long-text generation capabilities of large language models (LLMs).
The project includes a complete test dataset and evaluation code, with data sourced from platforms like Quora and Reddit. It provides diverse real-world challenges to assess LLM performance.
https://github.com/Quehry/HelloBench
Project: Time-MoE
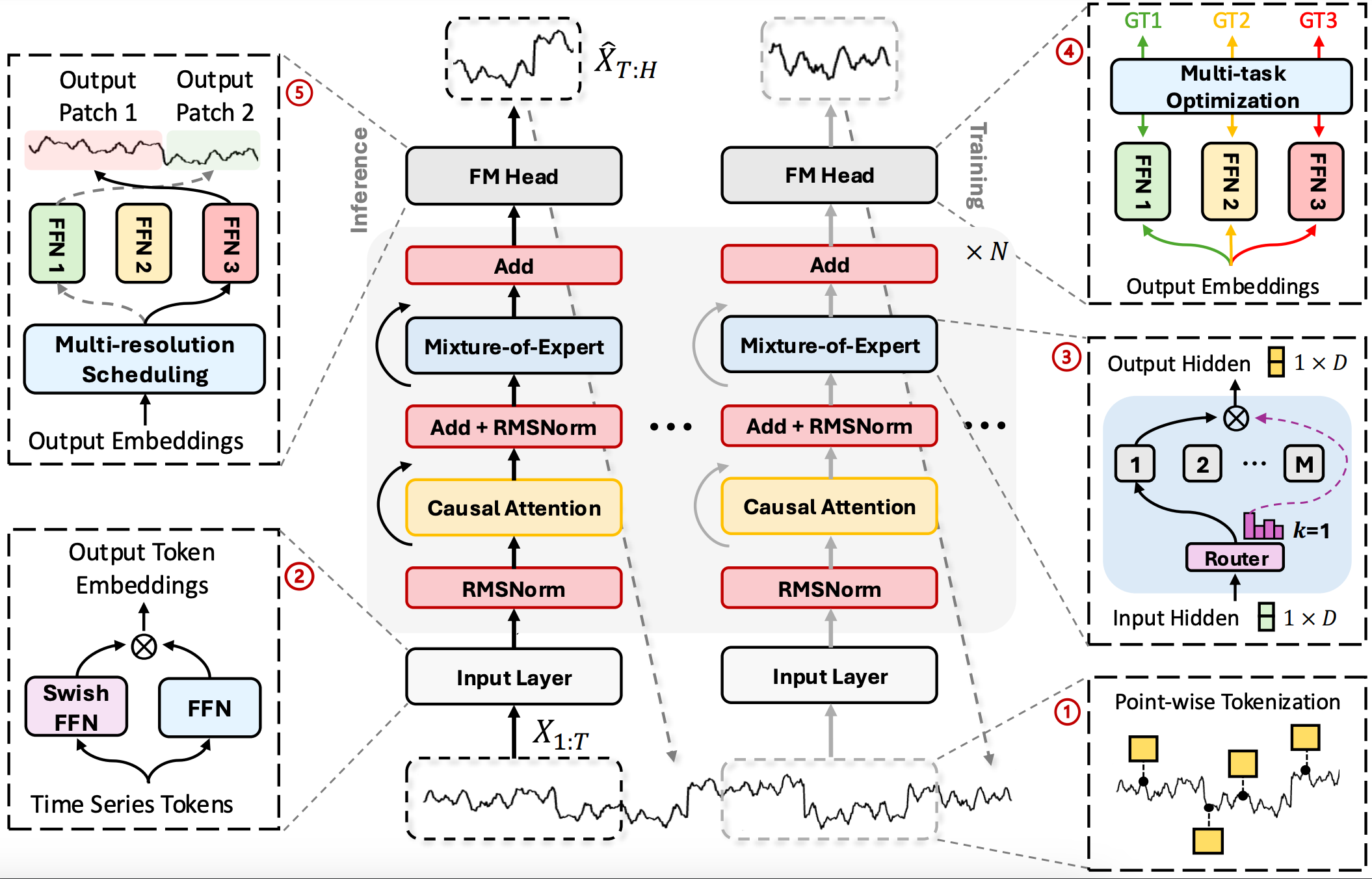
Time-MoE is a set of time-series foundational models based on a mixture-of-experts (MoE) architecture, designed for autoregressive tasks with support for any prediction range and a context length of up to 4096.
The architecture uses a sparse mixture of expert (MoE) design and is pre-trained on the new large-scale dataset, Time-300B. This setup scales the time-series model to over 240 million parameters, improving computational efficiency and reducing prediction costs.
