


Today's Open Source (2024-11-07): Browser-Use – Web Automation with LLM Integration
Explore innovative open-source projects like TableGPT2 for tabular data analysis, WebRL for self-evolving web agents, and more tools for enhancing data-driven tasks and web automation.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: TableGPT2

TableGPT2 is a large-scale decoder designed for data-intensive tasks, focused on interpreting and analyzing tabular data.
The model aims to bridge the gap between traditional large language model capabilities and the practical needs of tabular/structured data tasks, making it suitable for business intelligence, automated data-driven analysis, and applications involving databases or data warehouses.
https://huggingface.co/tablegpt/TableGPT2-7B
Project: WebRL

WebRL is a self-evolving online course learning framework designed to train web agents, particularly for the WebArena environment.
The project uses reinforcement learning techniques combined with automated curriculum learning strategies to enhance the performance and adaptability of web agents.
WebRL provides multiple model checkpoints and training scripts, allowing users to customize training and evaluation.
https://github.com/THUDM/WebRL
Project: AndroidLab
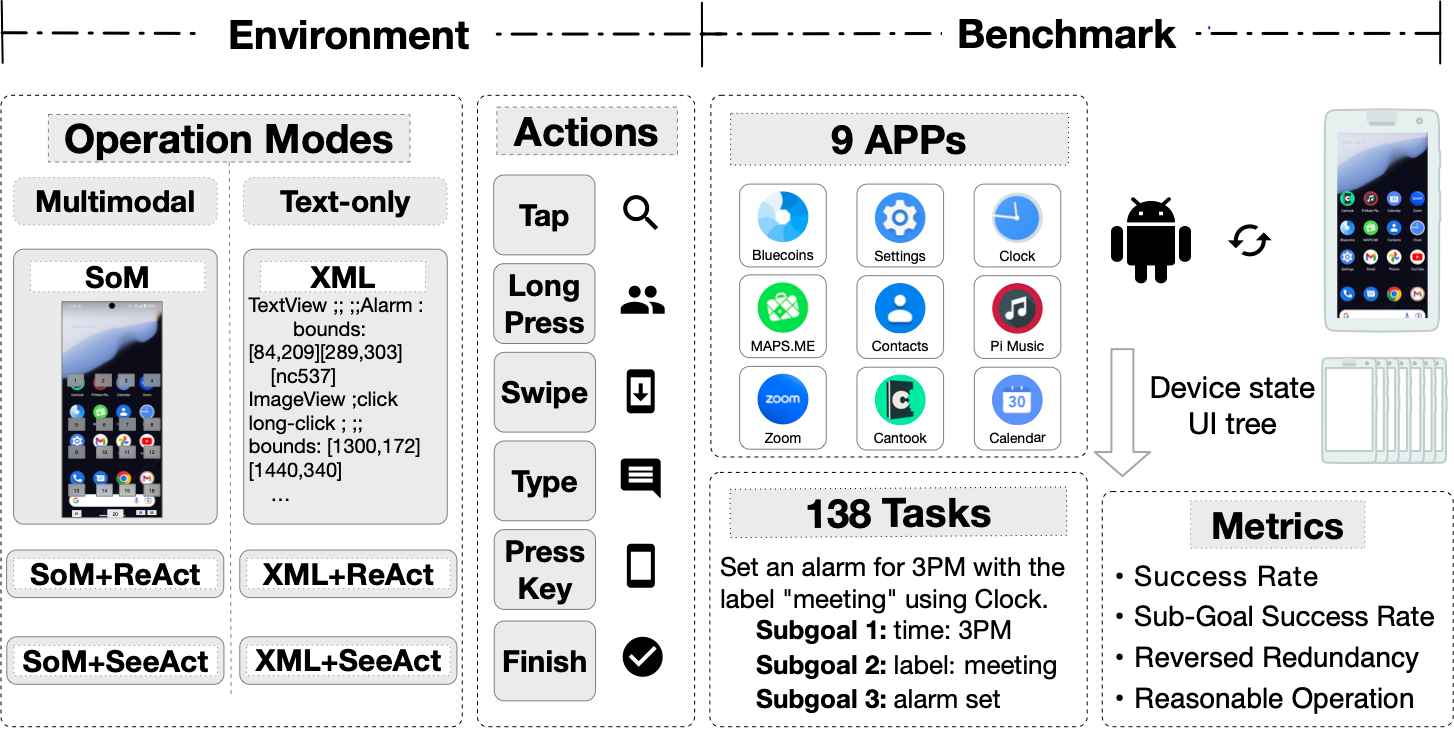
AndroidLab is a systematic Android agent framework that includes an operational environment and reproducible benchmark tests.
The benchmarks include predefined Android virtual devices and 138 tasks across nine applications.
The project offers two execution modes: AVD (arm64) on Mac and Docker (x86_64) on Linux, with a complete evaluation framework to assess the performance of various Android agents.
https://github.com/THUDM/Android-Lab
Project: LongRAG

The LongRAG project introduces a new framework that combines long-context language models (LLMs) with retrieval-augmented generation (RAG).
In traditional RAG frameworks, the retrieval units are typically short, causing the retriever to search a large corpus, while the reader extracts answers from short retrieval units.
LongRAG significantly increases the length of the retrieval unit to 4K tokens, aiming to address this imbalance in design.
https://github.com/TIGER-AI-Lab/LongRAG
Project: askrepo

askrepo is a tool for source code reading that leverages large language models (LLMs).
It reads the contents of Git-managed text files in a specified directory and sends them to the Google Gemini API to provide answers based on given prompt questions.
The tool is mainly used for analyzing source code and answering related questions, ideal for developers who need to quickly understand code functionality.
https://github.com/laiso/askrepo
Project: Browser-Use

Browser-Use is an open-source web automation library that supports interaction with any language model (LLM).
Through a simple interface, users can enable LLMs to interact with websites and perform tasks such as data scraping, information querying, and more.
The project supports multi-tab management, interactive element detection, and XPath extraction, and can handle dynamic content.

I like the browser-use, I will explore it for web scraping. any idea what website it can't scrape? e.g LinkedIn data?