


Today's Open Source (2024-11-15): Omnivision: A Multimodal Model Optimized for Edge Devices
Discover cutting-edge open-source AI projects like Omnivision, Athene-V2-Chat, and RAG-Diffusion, offering powerful multimodal models, enhanced training, and advanced capabilities.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: Omnivision

Omnivision is a compact multimodal model with 968M parameters, capable of processing both visual and text inputs, optimized specifically for edge devices.
The model is an enhancement of the LLaVA architecture, significantly reducing the number of image tokens, thereby lowering latency and computational costs.
By utilizing trusted data for DPO training, Omnivision delivers more reliable results, making it suitable for tasks such as visual question answering and image captioning.
https://huggingface.co/NexaAIDev/omnivision-968M
Project: Athene-V2-Chat

Athene-V2-Chat-72B is a large language model with open-source weights, whose performance is comparable to GPT-4o across multiple benchmarks.
The model is trained using reinforcement learning with human feedback (RLHF), based on the Qwen-2.5-72B-Instruct model. Athene-V2-Chat-72B excels in chat, math, and programming tasks.
Its sibling model, Athene-V2-Agent-72B, outperforms GPT-4o in complex function calls and agent-based applications.
https://huggingface.co/Nexusflow/Athene-V2-Chat
Project: Lingma SWE-GPT

Lingma SWE-GPT is an open-source large language model specifically designed for software improvement.
Based on the Qwen series base models, Lingma SWE-GPT enhances its ability to solve complex software engineering tasks through additional training with software engineering development process data.
The model is aimed at enhancing various aspects of software development through intelligent assistance.
https://github.com/LingmaTongyi/Lingma-SWE-GPT
Project: LLM2CLIP
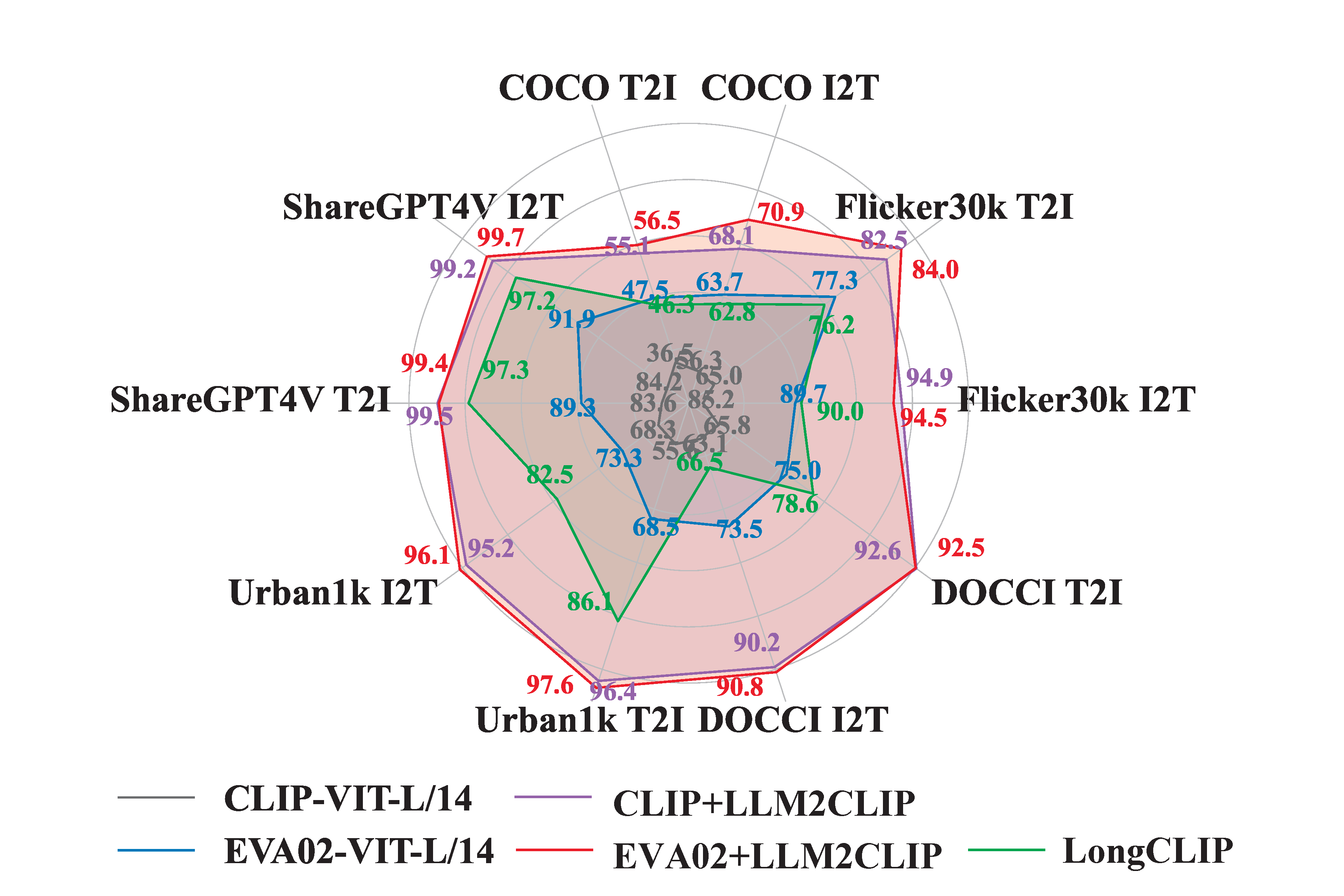
The LLM2CLIP project enhances CLIP’s multimodal learning ability by using large language models (LLM) as a powerful text teacher for the CLIP visual encoder.
This project addresses the limitations of existing CLIP models in text comprehension and context window handling by expanding the input window and improving text understanding, leading to richer text-image alignment.
LLM2CLIP is fine-tuned on purely English corpora, surpassing the standard Chinese CLIP model.
https://github.com/microsoft/LLM2CLIP
Project: Promptwright

Promptwright is a Python library developed by Stacklok, designed to generate large synthetic datasets using local LLMs.
The library provides a flexible and easy-to-use interface that enables users to generate prompt-based synthetic datasets.
Promptwright was originally derived from redotvideo/pluto but has been extensively rewritten to generate datasets using local LLM models.
The library integrates with Ollama, allowing users to easily pull models and run Promptwright.
https://github.com/StacklokLabs/promptwright
Project: RAG-Diffusion

RAG-Diffusion is a region-aware text-to-image generation method that achieves precise layout composition through region descriptions.
The method allows fine-grained spatial control through region prompts or combinations, solving the problem of insufficient control in multi-region generation seen in previous methods.
RAG-Diffusion breaks down multi-region generation into two sub-tasks: region hard-binding and region soft-fine-tuning, ensuring correct execution of region prompts and eliminating visual boundaries to enhance interaction between adjacent regions.
Additionally, RAG-Diffusion allows users to modify specific regions without relying on additional patching models, while keeping other regions unchanged.
