


Top 10 Key Metrics: The Ultimate AI Model Performance Rankings
Discover the latest AI model rankings in quality, speed, cost, and more. Find the best performers for your AI needs in our comprehensive review.


Today, let's review the latest rankings of mainstream AI models in various aspects, including quality, speed, cost, conversational ability, reasoning ability, coding, and response time.
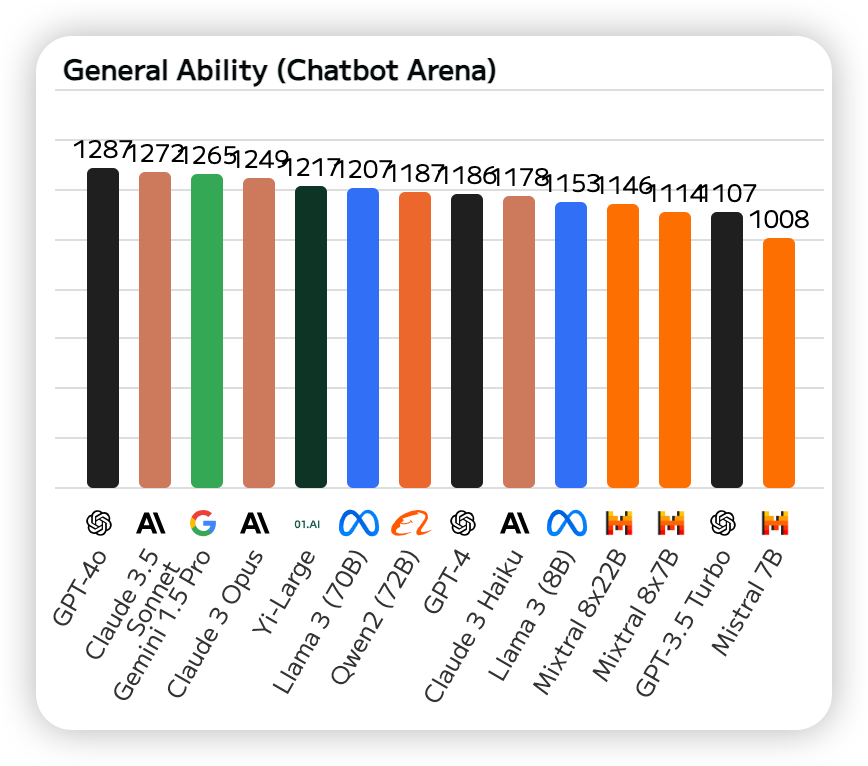
1. Conversational Ability
Chatbot Arena is a crowdsourced large model evaluation benchmark.
It provides a platform for developers and researchers to release, test, and compare different types of chatbots. Here are the top rankings according to Chatbot Arena.
The top three are GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro.
2. Reasoning Ability
MMLU (Massive Multitask Language Understanding) is a comprehensive assessment covering 57 tasks including basic math, US history, computer science, and law.
It requires models to demonstrate a broad knowledge base and problem-solving abilities. Here are the latest AI model rankings based on MMLU.
The top three are GPT-4o, Claude 3.5 Sonnet, and Claude 3 Opus.

3. Programming Ability
HumanEval is a dataset for evaluating code generation models, consisting of 164 programming problems. Each problem includes a function signature, docstring, function body, and several unit tests.
These problems cover language understanding, reasoning, algorithms, and simple mathematics.
The latest rankings based on HumanEval show the top three as Claude 3.5 Sonnet, GPT-4o, and GPT-4.

4. Context Window
The context window refers to the maximum number of combined input and output tokens.
A larger context window is crucial for workflows involving RAG (Retrieval-Augmented Generation) and large models, which often need to reason over and retrieve information from large datasets.
The top three are Gemini 1.5 Pro, Claude 3.5 Sonnet, and Claude 3 Opus.

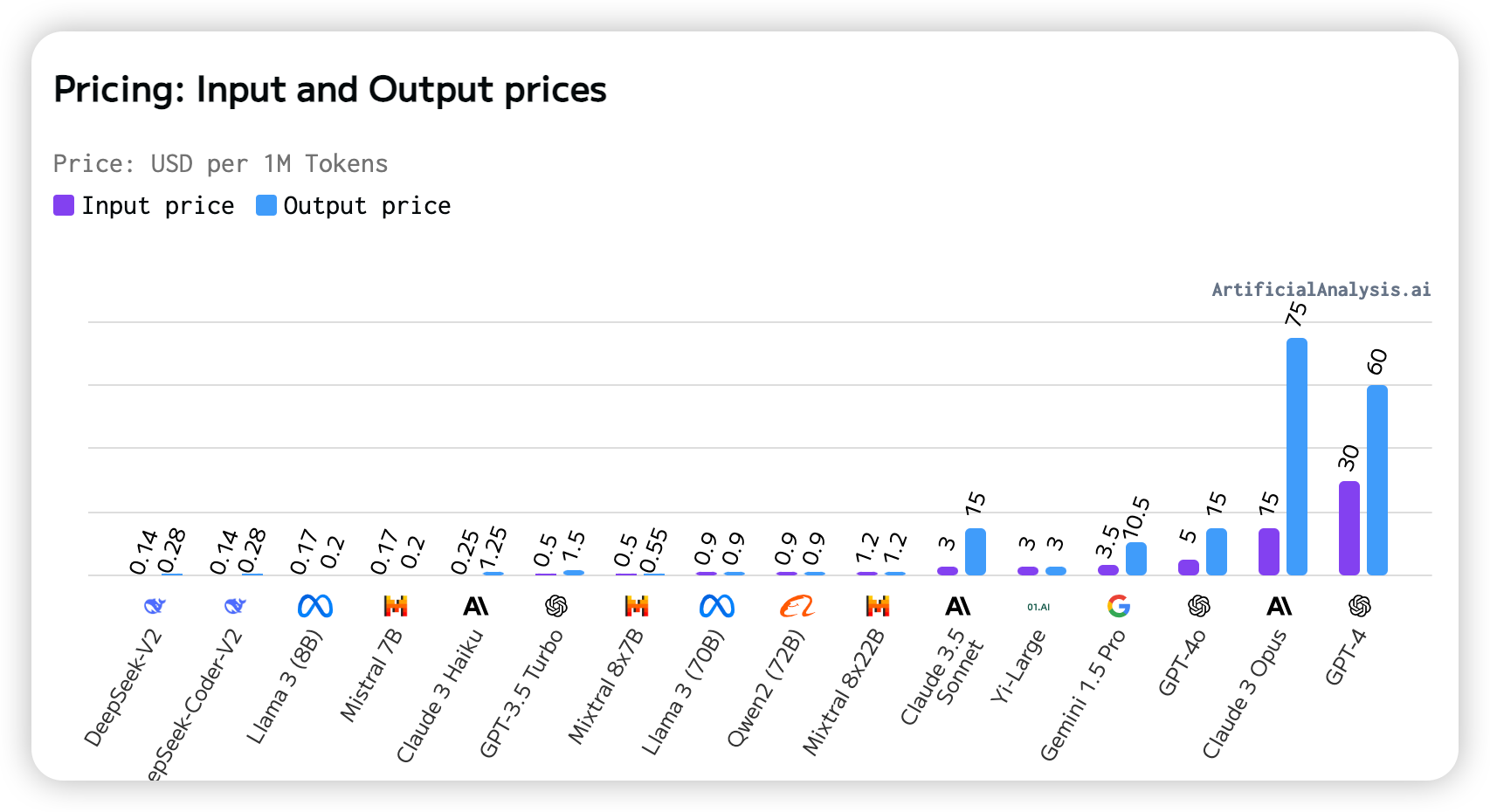
5. Cost per Input/Output
The cost is measured in dollars per million tokens. Lower rankings indicate cheaper models.
Here, China's DeepSeek model is the cheapest, while GPT-4 is the most expensive.
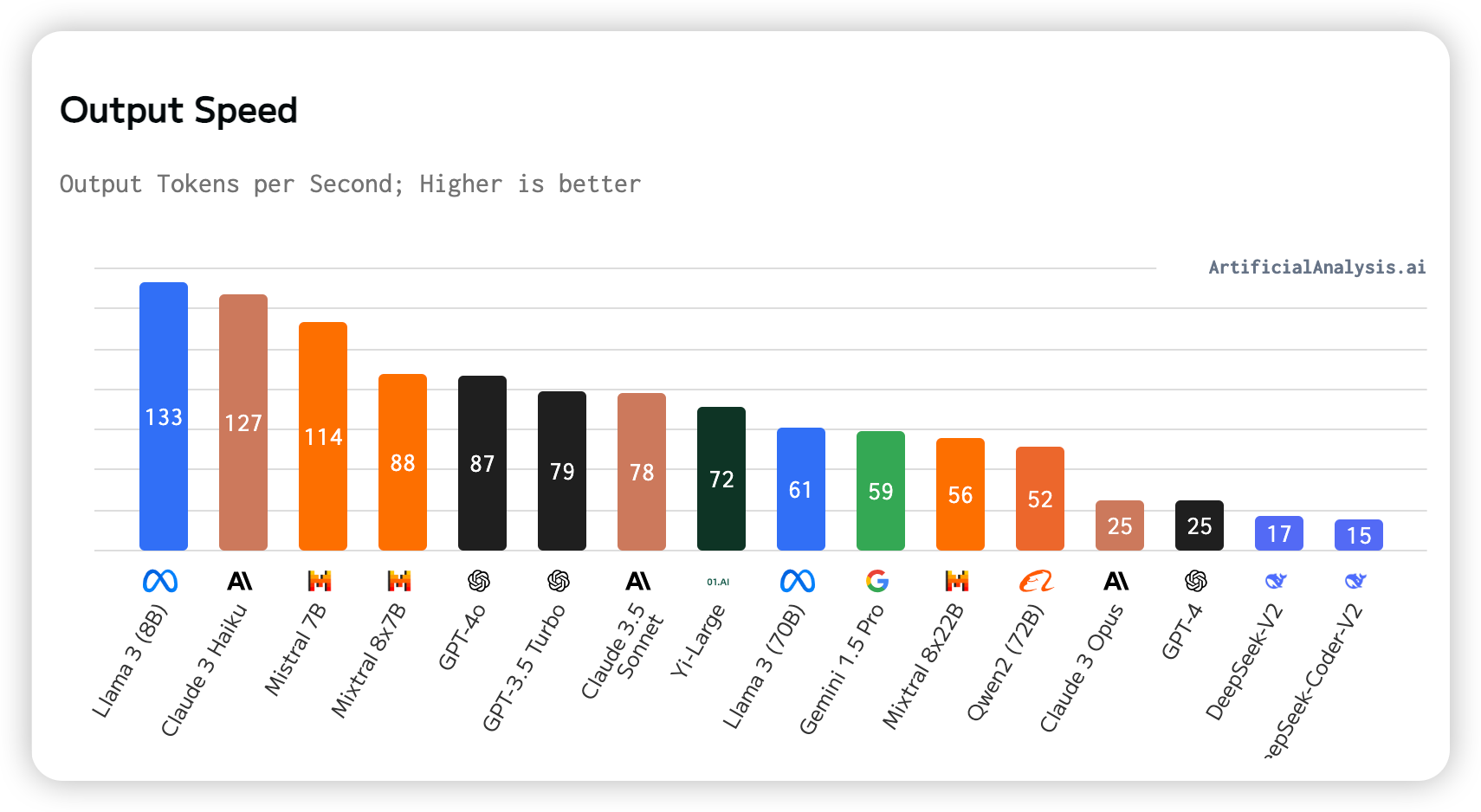
6. Output Speed
This measures the number of tokens a model can generate per second.
The fastest model is Llama 3 (8B), while the slowest is DeepSeek-Coder-V2.
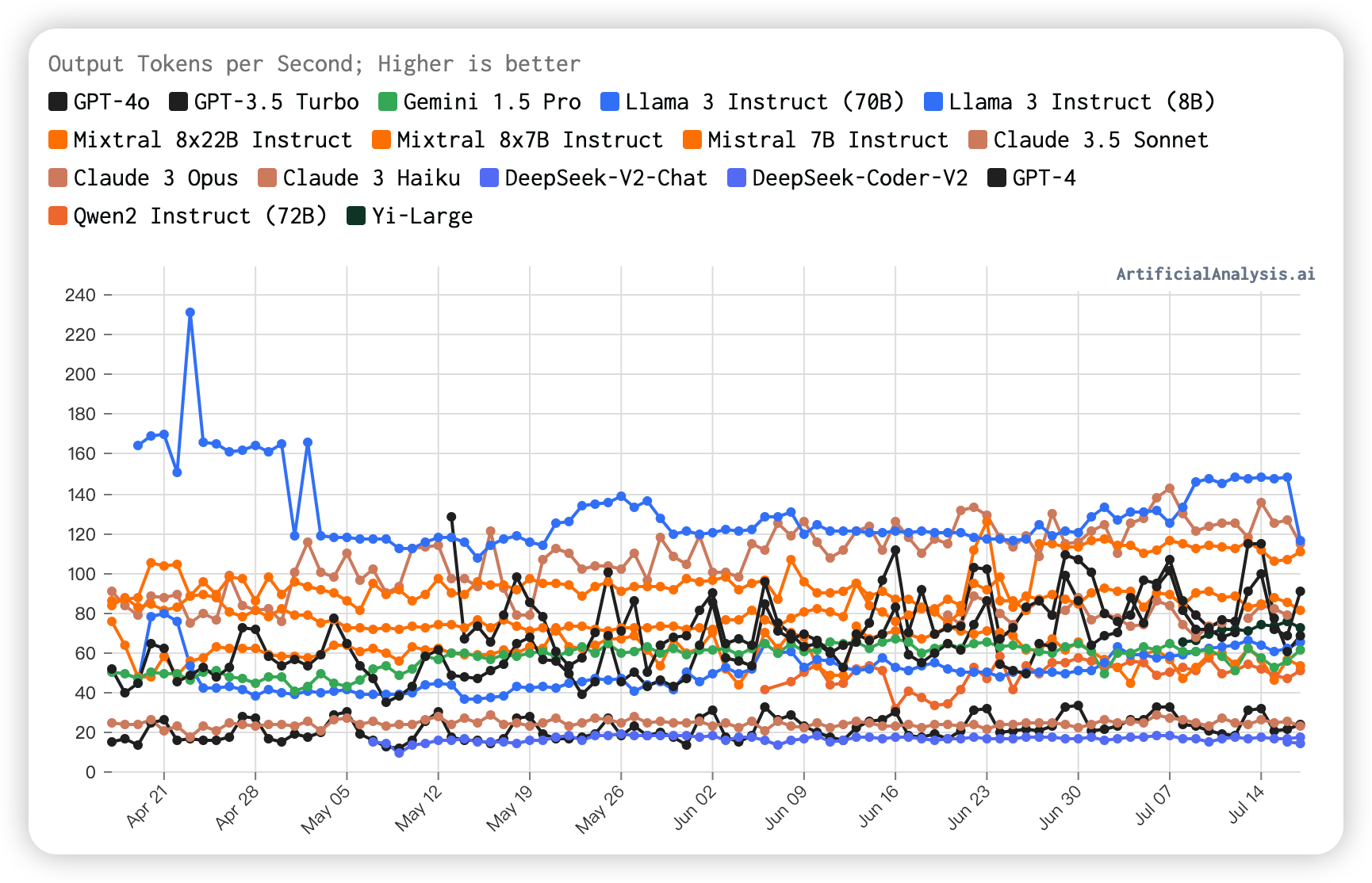
7. Output Speed Over Time
The graph shows that Llama 3 Instruct (8B) maintains a high output speed, though it has recently declined slightly.
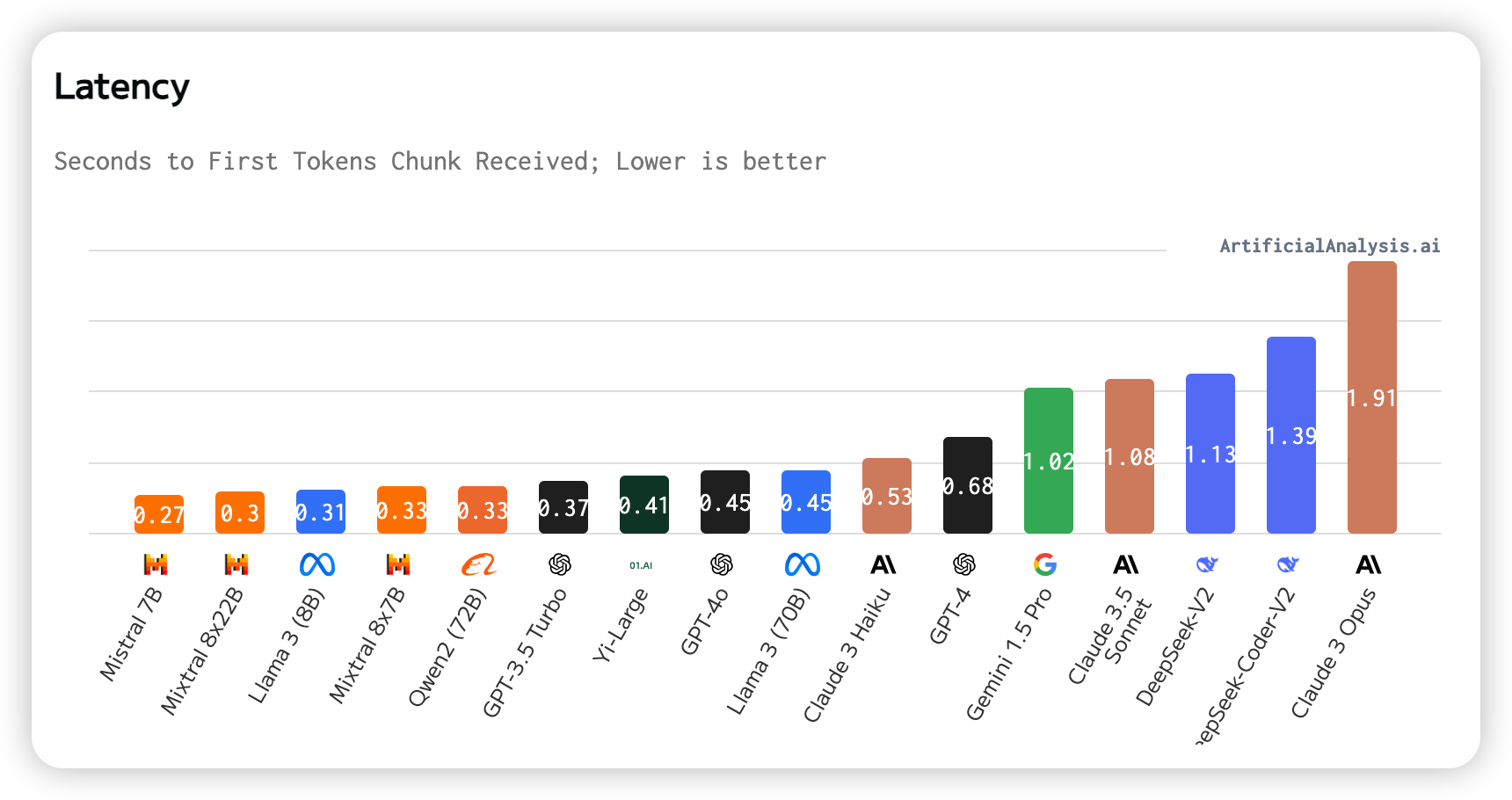
8. Latency
Latency is the time taken to receive the first token after sending an API request.
Mistral 7B has the lowest latency, while Claude 3 Opus has the highest.
9. Latency Over Time
The graph clearly shows that Claude 3 Opus consistently has high latency, while Gemini 1.5 Pro has shown significant improvement.
Other models generally have low latency.

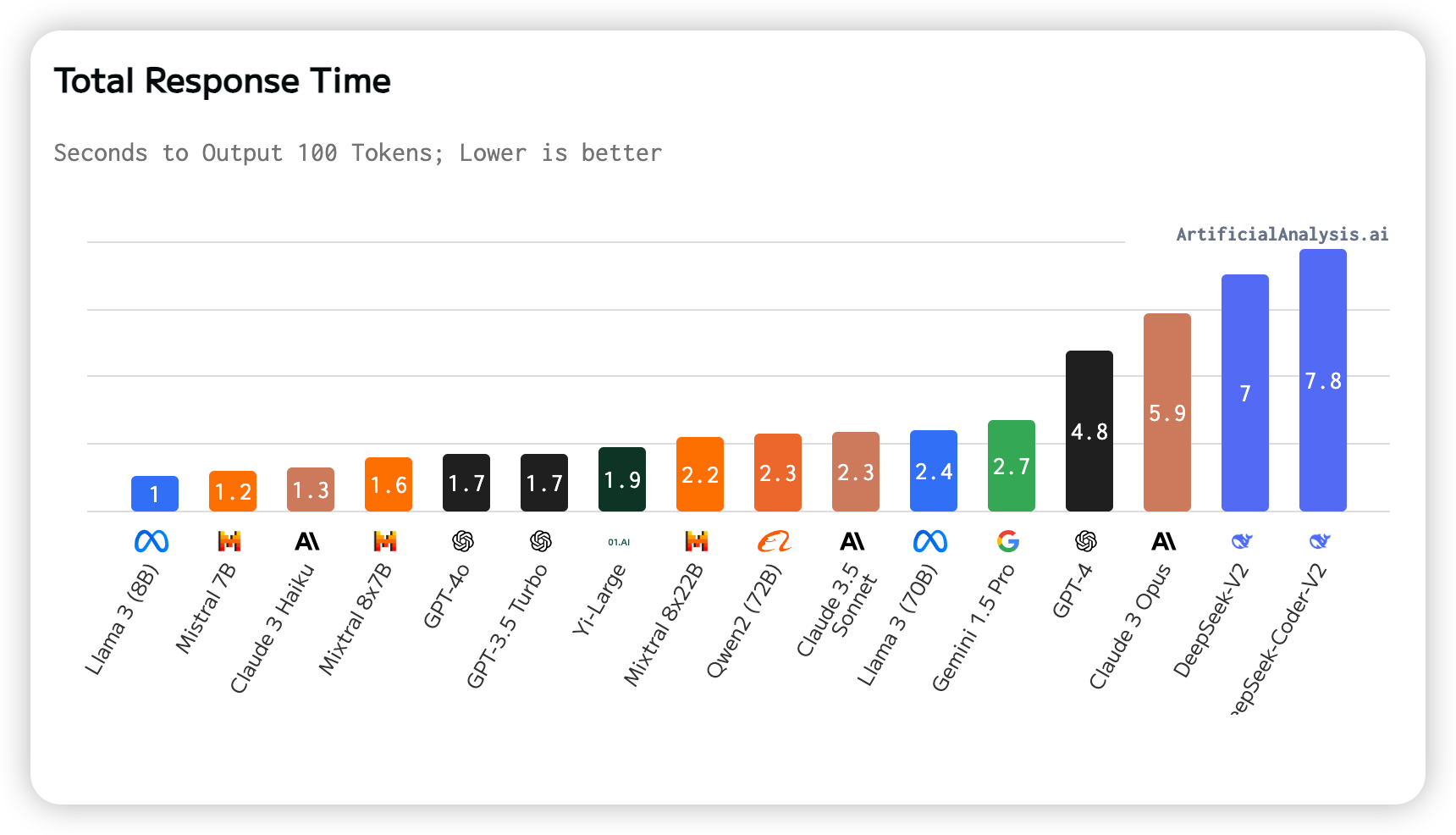
10. Total Response Time
Total response time is the time required to receive 100 tokens.
This is estimated based on latency (time to receive the first token) and output speed (tokens per second).
The graph shows that Llama 3 (8B) has the shortest total response time, while DeepSeek-Coder-V2 has the longest.
Conclusion
The performance of large models in various aspects is crucial for developing AI products. Evaluating these performances helps us choose the right models and API providers.
Whether optimizing quality, enhancing speed, controlling costs, or needing specific application abilities, these models offer a wealth of options.
