


Today's Open Source (2024-11-18): DIAMOND - A New Reinforcement Learning Agent
Explore cutting-edge AI projects like DIAMOND, AG2, DeeR-VLA, and Promptimizer, advancing reinforcement learning, agent collaboration, and prompt optimization.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: DIAMOND

DIAMOND is a reinforcement learning agent trained within a diffusion world model.
This project gained attention at NeurIPS 2024, showcasing its potential applications in environments such as Atari and CSGO.
By leveraging diffusion models, DIAMOND enables autoregressive imagination and decision-making in virtual environments, offering an innovative approach to reinforcement learning.
https://github.com/eloialonso/diamond
Project: AG2

AG2 is an open-source programming framework designed to build AI agents and facilitate collaboration among multiple agents to solve tasks.
AG2 aims to simplify the development and research of intelligent agents, similar to how PyTorch revolutionized deep learning.
It provides functionalities for agent interaction, and supports various large language models, tool usage, automation, human-AI workflows, and multi-agent dialogue modes.
Project: DeeR-VLA
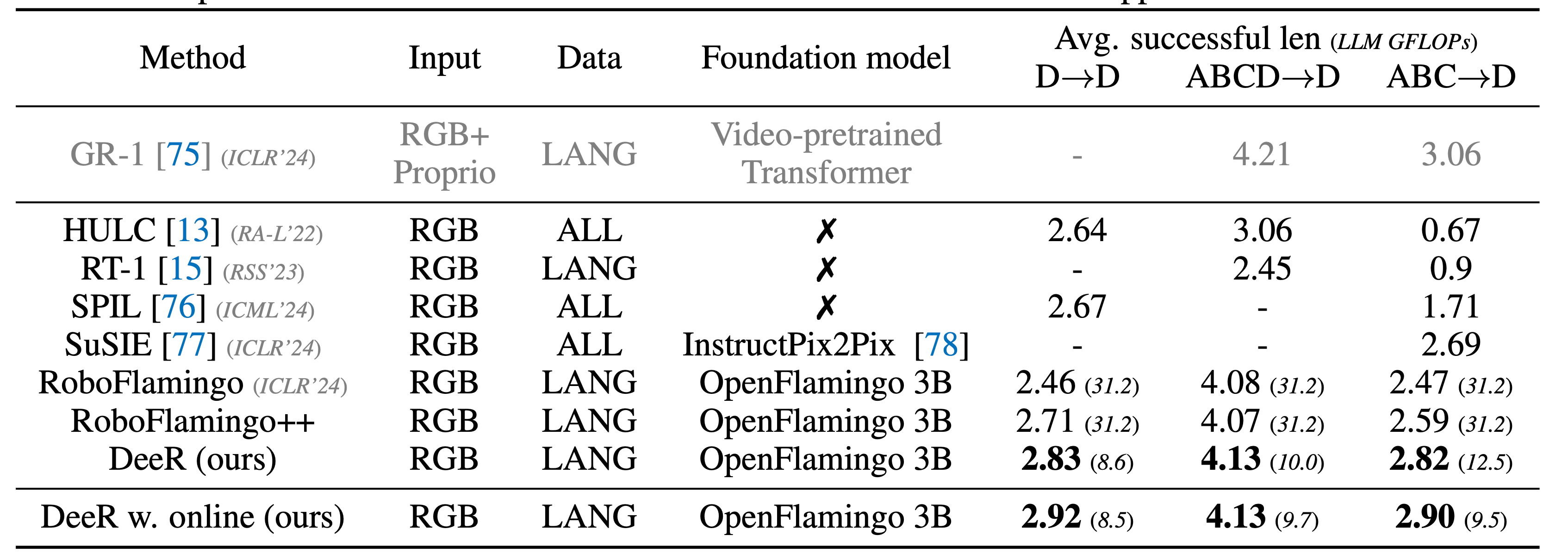
DeeR-VLA is a multimodal large language model (MLLM) dynamic reasoning framework designed for efficient robotic execution.
By implementing a dynamic early exit strategy, DeeR-VLA adjusts the size of activated MLLMs automatically based on the complexity of each scenario, addressing efficiency challenges.
This approach leverages a multi-exit architecture to terminate processing once the appropriate model size is activated, avoiding redundant computation.
On the CALVIN robotic manipulation benchmark, DeeR achieved a 5.2–6.5x reduction in LLM computational cost and a 2–6x reduction in GPU memory usage, with no compromise on performance.
https://github.com/yueyang130/DeeR-VLA
Project: Promptimizer

Optimizer is an experimental prompt optimization library designed to systematically improve prompts for AI systems.
By providing an initial prompt, dataset, and custom evaluator (optionally with human feedback), Promptimizer runs an optimization loop to generate an improved prompt aimed at outperforming the original.
https://github.com/hinthornw/promptimizer
Project: RLT
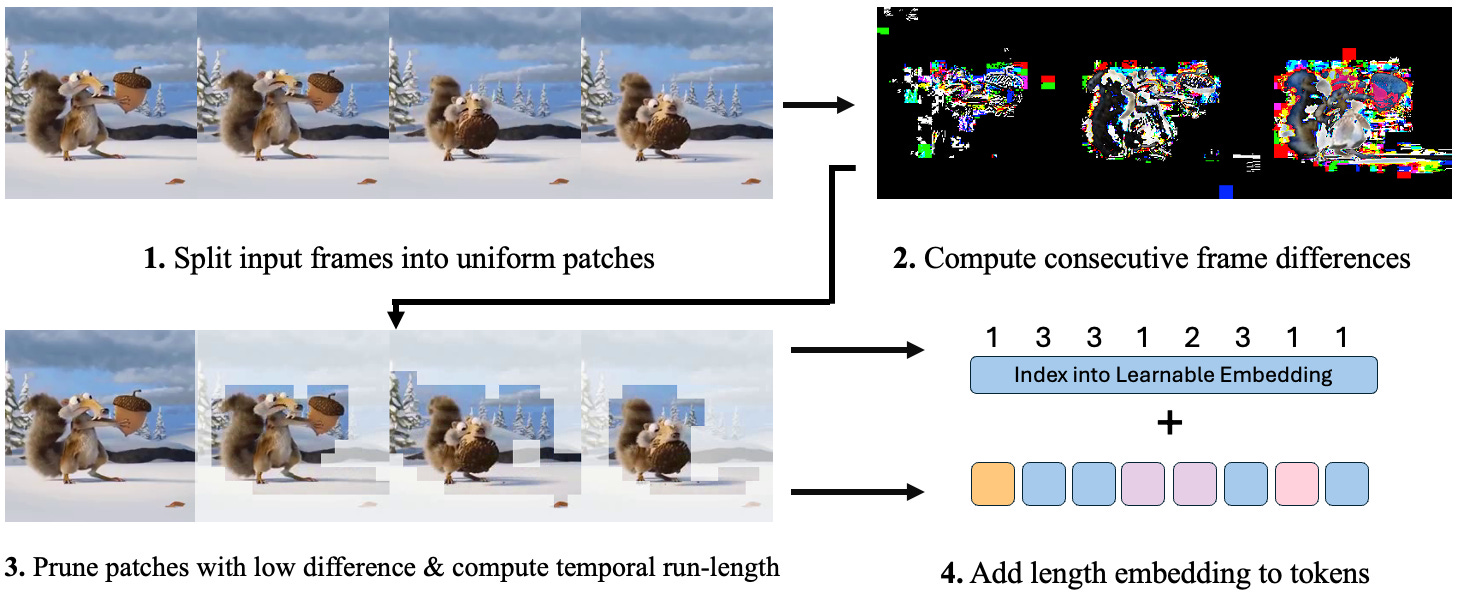
This project introduces a new method called Run-Length Tokenization (RLT) to accelerate the training of video Transformers.
RLT effectively identifies and removes redundant temporal segments before model inference, replacing them with a single segment and positional encoding to reduce the number of input tokens.
This method requires minimal overhead, does not need fine-tuning for different datasets, and significantly speeds up training without compromising model performance.
https://github.com/rccchoudhury/rlt
Project: Beepo

Beepo-22B is a fine-tuned model based on Mistral-Small-Instruct-2409, designed to reduce censorship while maintaining excellent instruction-following capabilities.
The model supports Alpaca-style instruction prompts and has undergone de-censorship fine-tuning to better respond to user instructions.
