


Today’s Open Source (2024–10–09): Speech Recognition System Reverb ASR
Discover cutting-edge open-source projects like Reverb ASR, Gptme, Voice Chat PDF, TPI-LLM, Voice-Pro, and Podcastfy for AI, speech recognition, and more.

Here are some interesting AI open-source models and frameworks I wanted to share today:
Project: Reverb ASR

Reverb ASR is an open-source automatic speech recognition system, trained on 200,000 hours of English speech data, which was meticulously transcribed by humans.
This project has implemented the world’s most accurate English ASR system with an efficient model architecture, supporting operation on either CPU or GPU.
Reverb ASR allows users to control the verbatim level of the output transcription, making it suitable for scenarios like readable transcriptions or audio editing.
Project: Gptme
Gptme is a personal AI assistant that runs in the terminal, equipped with local tools to execute code, use the terminal, browse the web, and handle visual processing.
It serves as a local alternative to ChatGPT’s “code interpreter,” free from issues like software limitations, network access restrictions, timeouts, or privacy concerns, making it especially useful for knowledge-based tasks like programming.
https://github.com/ErikBjare/gptme
Project: voice-chat-pdf
Voice Chat with PDFs is a project based on OpenAI’s real-time API that allows users to interact with PDF documents via voice.
The project extends openai/openai-realtime-console with LlamaIndexTS, offering a simple retrieval-augmented generation (RAG) system.
Users can engage with documents through voice activity detection or manual keypress-based conversation modes.
https://github.com/run-llama/voice-chat-pdf
Project: TPI-LLM
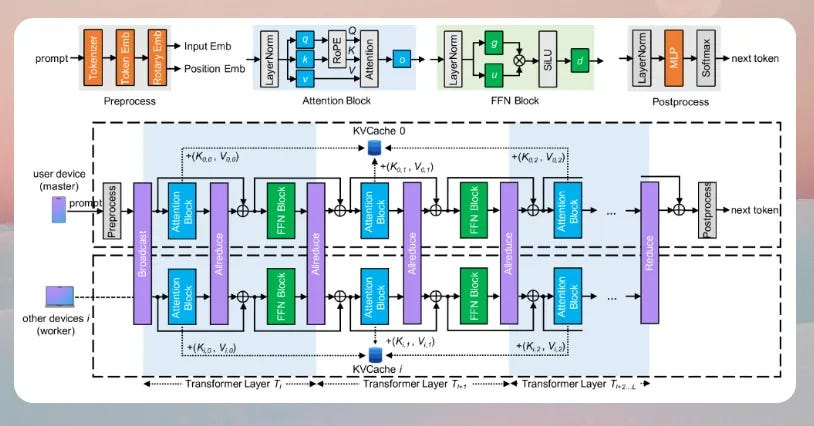
TPI-LLM is a high-performance tensor parallel inference system designed for low-resource edge devices, aiming to bring large language model (LLM) capabilities to the edge.
The system solves cloud LLM service privacy issues by performing tensor parallel inference across multiple edge devices, combined with a sliding window memory scheduler to minimize memory usage.
TPI-LLM enables large-scale models to run efficiently on resource-constrained devices and significantly reduces inference latency.
https://github.com/lizonghang/tpi-llm
Project: Voice-Pro
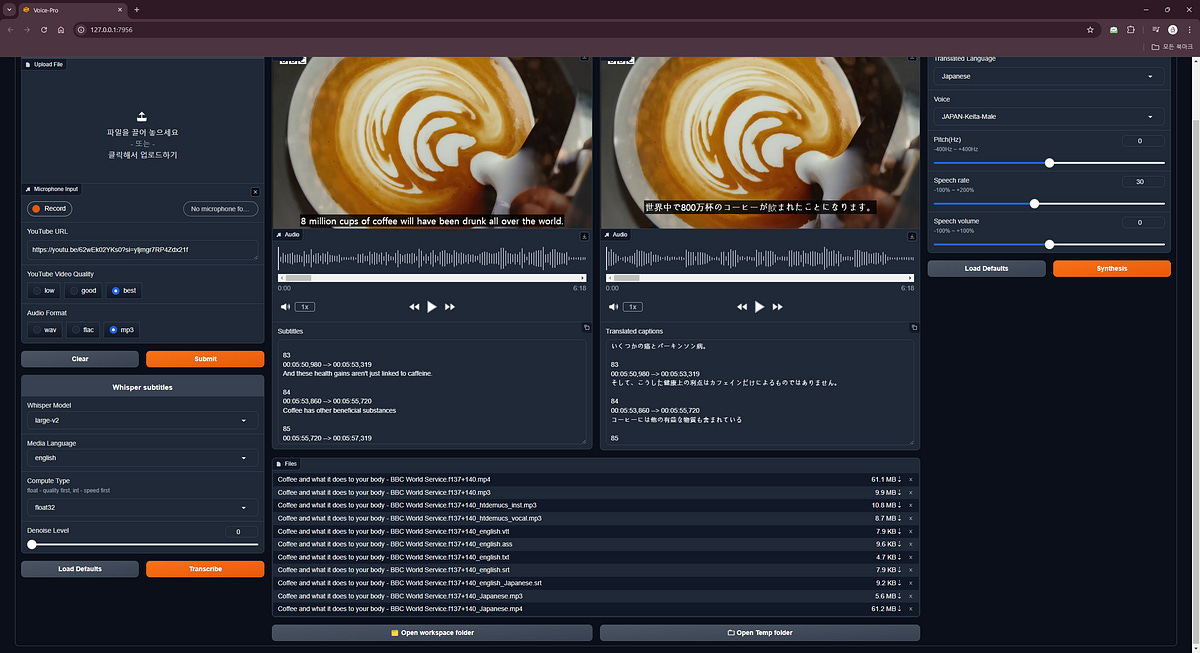
Voice-Pro is an integrated solution that provides tools for subtitles, translation, and text-to-speech (TTS).
Users can add multilingual subtitles and audio to videos through the project, supporting real-time translation and multiple audio output formats.
The project leverages the OpenAI Whisper model and open-source translation and TTS tools, offering a simple one-click installation and a Gradio Web-UI interface, making it ideal for multilingual video production and global market expansion.
https://github.com/abus-aikorea/voice-pro
Project: Podcastfy

Podcastfy is an open-source Python package that utilizes generative AI to transform web content, PDFs, and text into engaging, multilingual audio conversations.
Unlike UI tools that primarily focus on note-taking or research summarization, Podcastfy specializes in generating customized and scalable conversational transcriptions and audio from various text sources.
